Core Classes
pyspark.sql.SparkSession
The entry point to programming Spark with the Dataset and DataFrame API.
-> pyspark 사용 시 스파크 세션을 할당해야 spark 프로그래밍을 시작할 수 있음
pyspark.sql.Catalog
User-facing catalog API, accessible through SparkSession.catalog.
- 카탈로그
- 메타스토어에 접근하기 위한 인터페이스
- 메타스토어: 메타정보를 보관하고 사용자의 요청에 따라 관련 정보를 제공하는 곳
(출처: https://wikidocs.net/28353 )
- 메타스토어: 메타정보를 보관하고 사용자의 요청에 따라 관련 정보를 제공하는 곳
- 즉, 데이터베이스, 로컬 및 외부 테이블, 함수, 테이블 컬럼, 임시 뷰의 데이터 목록
(출처: https://mallikarjuna_g.gitbooks.io/spark/content/spark-sql-Catalog.html#contract ) - 테이블, 데이터베이스 리스팅 하는 데 사용
- 메타스토어에 접근하기 위한 인터페이스
pyspark.sql.DataFrame
A distributed collection of data grouped into named columns.
pyspark.sql.Column
A column in a DataFrame.
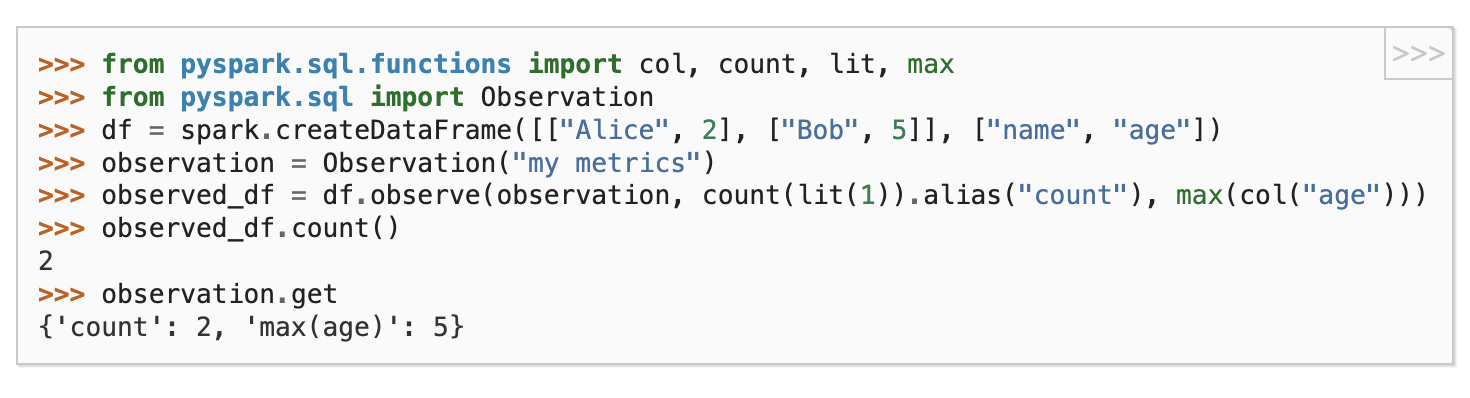
pyspark.sql.Observation
Class to observe (named) metrics on a DataFrame.
원하는 count, max 등 기본 api를 이용해 나만의 metirc을 정의할 수 있고 한꺼번에 얻을 수 있도록 도와주는 듯?
metric pipeline 같은 느낌..
pyspark.sql.Row
pyspark.sql.GroupedData
pyspark.sql.PandasCogroupedOps
pyspark.sql.DataFrameNaFunctions
pyspark.sql.DataFrameStatFunctions
pyspark.sql.Window
pyspark.sql.DataFrameReader
pyspark.sql.DataFrameWriter
Spark Session
- pyspark.sql.SparkSession.builder.appName
- pyspark.sql.SparkSession.builder.config
- pyspark.sql.SparkSession.builder.enableHiveSupport
- pyspark.sql.SparkSession.builder.getOrCreate
- pyspark.sql.SparkSession.builder.master
- pyspark.sql.SparkSession.catalog
- pyspark.sql.SparkSession.conf
- pyspark.sql.SparkSession.createDataFrame
- pyspark.sql.SparkSession.getActiveSession
- pyspark.sql.SparkSession.newSession
- pyspark.sql.SparkSession.range
- pyspark.sql.SparkSession.read
- pyspark.sql.SparkSession.readStream
- pyspark.sql.SparkSession.sparkContext
- pyspark.sql.SparkSession.sql
- pyspark.sql.SparkSession.stop
- pyspark.sql.SparkSession.streams
- pyspark.sql.SparkSession.table
- pyspark.sql.SparkSession.udf
- pyspark.sql.SparkSession.version
- pyspark.sql.DataFrameReader.csv
- pyspark.sql.DataFrameReader.format
- pyspark.sql.DataFrameReader.jdbc
- pyspark.sql.DataFrameReader.json
- pyspark.sql.DataFrameReader.load
- pyspark.sql.DataFrameReader.option
- pyspark.sql.DataFrameReader.options
- pyspark.sql.DataFrameReader.orc
- pyspark.sql.DataFrameReader.parquet
- pyspark.sql.DataFrameReader.schema
- pyspark.sql.DataFrameReader.table
- pyspark.sql.DataFrameReader.text
- pyspark.sql.DataFrameWriter.bucketBy
- pyspark.sql.DataFrameWriter.csv
- pyspark.sql.DataFrameWriter.format
- pyspark.sql.DataFrameWriter.insertInto
- pyspark.sql.DataFrameWriter.jdbc
- pyspark.sql.DataFrameWriter.json
- pyspark.sql.DataFrameWriter.mode
- pyspark.sql.DataFrameWriter.option
- pyspark.sql.DataFrameWriter.options
- pyspark.sql.DataFrameWriter.orc
- pyspark.sql.DataFrameWriter.parquet
- pyspark.sql.DataFrameWriter.partitionBy
- pyspark.sql.DataFrameWriter.save
- pyspark.sql.DataFrameWriter.saveAsTable
- pyspark.sql.DataFrameWriter.sortBy
- pyspark.sql.DataFrameWriter.text
- pyspark.sql.DataFrame.agg
- pyspark.sql.DataFrame.alias
- pyspark.sql.DataFrame.approxQuantile
- pyspark.sql.DataFrame.cache
- pyspark.sql.DataFrame.checkpoint
- pyspark.sql.DataFrame.coalesce
- pyspark.sql.DataFrame.colRegex
- pyspark.sql.DataFrame.collect
- pyspark.sql.DataFrame.columns
- pyspark.sql.DataFrame.corr
- pyspark.sql.DataFrame.count
- pyspark.sql.DataFrame.cov
- pyspark.sql.DataFrame.createGlobalTempView
- pyspark.sql.DataFrame.createOrReplaceGlobalTempView
- pyspark.sql.DataFrame.createOrReplaceTempView
- pyspark.sql.DataFrame.createTempView
- pyspark.sql.DataFrame.crossJoin
- pyspark.sql.DataFrame.crosstab
- pyspark.sql.DataFrame.cube
- pyspark.sql.DataFrame.describe
- pyspark.sql.DataFrame.distinct
- pyspark.sql.DataFrame.drop
- pyspark.sql.DataFrame.dropDuplicates
- pyspark.sql.DataFrame.drop_duplicates
- pyspark.sql.DataFrame.dropna
- pyspark.sql.DataFrame.dtypes
- pyspark.sql.DataFrame.exceptAll
- pyspark.sql.DataFrame.explain
- pyspark.sql.DataFrame.fillna
- pyspark.sql.DataFrame.filter
- pyspark.sql.DataFrame.first
- pyspark.sql.DataFrame.foreach
- pyspark.sql.DataFrame.foreachPartition
- pyspark.sql.DataFrame.freqItems
- pyspark.sql.DataFrame.groupBy
- pyspark.sql.DataFrame.head
- pyspark.sql.DataFrame.hint
- pyspark.sql.DataFrame.inputFiles
- pyspark.sql.DataFrame.intersect
- pyspark.sql.DataFrame.intersectAll
- pyspark.sql.DataFrame.isEmpty
- pyspark.sql.DataFrame.isLocal
- pyspark.sql.DataFrame.isStreaming
- pyspark.sql.DataFrame.join
- pyspark.sql.DataFrame.limit
- pyspark.sql.DataFrame.localCheckpoint
- pyspark.sql.DataFrame.mapInPandas
- pyspark.sql.DataFrame.mapInArrow
- pyspark.sql.DataFrame.na
- pyspark.sql.DataFrame.observe
- pyspark.sql.DataFrame.orderBy
- pyspark.sql.DataFrame.persist
- pyspark.sql.DataFrame.printSchema
- pyspark.sql.DataFrame.randomSplit
- pyspark.sql.DataFrame.rdd
- pyspark.sql.DataFrame.registerTempTable
- pyspark.sql.DataFrame.repartition
- pyspark.sql.DataFrame.repartitionByRange
- pyspark.sql.DataFrame.replace
- pyspark.sql.DataFrame.rollup
- pyspark.sql.DataFrame.sameSemantics
- pyspark.sql.DataFrame.sample
- pyspark.sql.DataFrame.sampleBy
- pyspark.sql.DataFrame.schema
- pyspark.sql.DataFrame.select
- pyspark.sql.DataFrame.selectExpr
- pyspark.sql.DataFrame.semanticHash
- pyspark.sql.DataFrame.show
- pyspark.sql.DataFrame.sort
- pyspark.sql.DataFrame.sortWithinPartitions
- pyspark.sql.DataFrame.sparkSession
- pyspark.sql.DataFrame.stat
- pyspark.sql.DataFrame.storageLevel
- pyspark.sql.DataFrame.subtract
- pyspark.sql.DataFrame.summary
- pyspark.sql.DataFrame.tail
- pyspark.sql.DataFrame.take
- pyspark.sql.DataFrame.toDF
- pyspark.sql.DataFrame.toJSON
- pyspark.sql.DataFrame.toLocalIterator
- pyspark.sql.DataFrame.toPandas
- pyspark.sql.DataFrame.to_pandas_on_spark
- pyspark.sql.DataFrame.transform
- pyspark.sql.DataFrame.union
- pyspark.sql.DataFrame.unionAll
- pyspark.sql.DataFrame.unionByName
- pyspark.sql.DataFrame.unpersist
- pyspark.sql.DataFrame.where
- pyspark.sql.DataFrame.withColumn
- pyspark.sql.DataFrame.withColumns
- pyspark.sql.DataFrame.withColumnRenamed
- pyspark.sql.DataFrame.withMetadata
- pyspark.sql.DataFrame.withWatermark
- pyspark.sql.DataFrame.write
- pyspark.sql.DataFrame.writeStream
- pyspark.sql.DataFrame.writeTo
- pyspark.sql.DataFrame.pandas_api
- pyspark.sql.DataFrameNaFunctions.drop
- pyspark.sql.DataFrameNaFunctions.fill
- pyspark.sql.DataFrameNaFunctions.replace
- pyspark.sql.DataFrameStatFunctions.approxQuantile
- pyspark.sql.DataFrameStatFunctions.corr
- pyspark.sql.DataFrameStatFunctions.cov
- pyspark.sql.DataFrameStatFunctions.crosstab
- pyspark.sql.DataFrameStatFunctions.freqItems
- pyspark.sql.DataFrameStatFunctions.sampleBy
- pyspark.sql.Column.alias
- pyspark.sql.Column.asc
- pyspark.sql.Column.asc_nulls_first
- pyspark.sql.Column.asc_nulls_last
- pyspark.sql.Column.astype
- pyspark.sql.Column.between
- pyspark.sql.Column.bitwiseAND
- pyspark.sql.Column.bitwiseOR
- pyspark.sql.Column.bitwiseXOR
- pyspark.sql.Column.cast
- pyspark.sql.Column.contains
- pyspark.sql.Column.desc
- pyspark.sql.Column.desc_nulls_first
- pyspark.sql.Column.desc_nulls_last
- pyspark.sql.Column.dropFields
- pyspark.sql.Column.endswith
- pyspark.sql.Column.eqNullSafe
- pyspark.sql.Column.getField
- pyspark.sql.Column.getItem
- pyspark.sql.Column.ilike
- pyspark.sql.Column.isNotNull
- pyspark.sql.Column.isNull
- pyspark.sql.Column.isin
- pyspark.sql.Column.like
- pyspark.sql.Column.name
- pyspark.sql.Column.otherwise
- pyspark.sql.Column.over
- pyspark.sql.Column.rlike
- pyspark.sql.Column.startswith
- pyspark.sql.Column.substr
- pyspark.sql.Column.when
- pyspark.sql.Column.withField
- ArrayType
- BinaryType
- BooleanType
- ByteType
- DataType
- DateType
- DecimalType
- DoubleType
- FloatType
- IntegerType
- LongType
- MapType
- NullType
- ShortType
- StringType
- StructField
- StructType
- TimestampType
- DayTimeIntervalType
- Normal Functions
- Math Functions
- Datetime Functions
- Collection Functions
- Partition Transformation Functions
- Aggregate Functions
- Window Functions
- Sort Functions
- String Functions
- UDF
- Misc Functions
- pyspark.sql.Window.currentRow
- pyspark.sql.Window.orderBy
- pyspark.sql.Window.partitionBy
- pyspark.sql.Window.rangeBetween
- pyspark.sql.Window.rowsBetween
- pyspark.sql.Window.unboundedFollowing
- pyspark.sql.Window.unboundedPreceding
- pyspark.sql.WindowSpec.orderBy
- pyspark.sql.WindowSpec.partitionBy
- pyspark.sql.WindowSpec.rangeBetween
- pyspark.sql.WindowSpec.rowsBetween
- pyspark.sql.GroupedData.agg
- pyspark.sql.GroupedData.apply
- pyspark.sql.GroupedData.applyInPandas
- pyspark.sql.GroupedData.avg
- pyspark.sql.GroupedData.cogroup
- pyspark.sql.GroupedData.count
- pyspark.sql.GroupedData.max
- pyspark.sql.GroupedData.mean
- pyspark.sql.GroupedData.min
- pyspark.sql.GroupedData.pivot
- pyspark.sql.GroupedData.sum
- pyspark.sql.PandasCogroupedOps.applyInPandas
- pyspark.sql.Catalog.cacheTable
- pyspark.sql.Catalog.clearCache
- pyspark.sql.Catalog.createExternalTable
- pyspark.sql.Catalog.createTable
- pyspark.sql.Catalog.currentDatabase
- pyspark.sql.Catalog.databaseExists
- pyspark.sql.Catalog.dropGlobalTempView
- pyspark.sql.Catalog.dropTempView
- pyspark.sql.Catalog.functionExists
- pyspark.sql.Catalog.isCached
- pyspark.sql.Catalog.listColumns
- pyspark.sql.Catalog.listDatabases
- pyspark.sql.Catalog.listFunctions
- pyspark.sql.Catalog.listTables
- pyspark.sql.Catalog.recoverPartitions
- pyspark.sql.Catalog.refreshByPath
- pyspark.sql.Catalog.refreshTable
- pyspark.sql.Catalog.registerFunction
- pyspark.sql.Catalog.setCurrentDatabase
- pyspark.sql.Catalog.tableExists
- pyspark.sql.Catalog.uncacheTable
'Spark & Hadoop' 카테고리의 다른 글
| [SparkByExamples] Pyspark Tutorial (0) | 2022.11.04 |
|---|
