Understanding Batch Normalization with Examples in Numpy and Tensorflow with Interactive Code
So for today, I am going to explore batch normalization (Batch Normalization: Accelerating Deep Network Training by Reducing Internal…
towardsdatascience.com
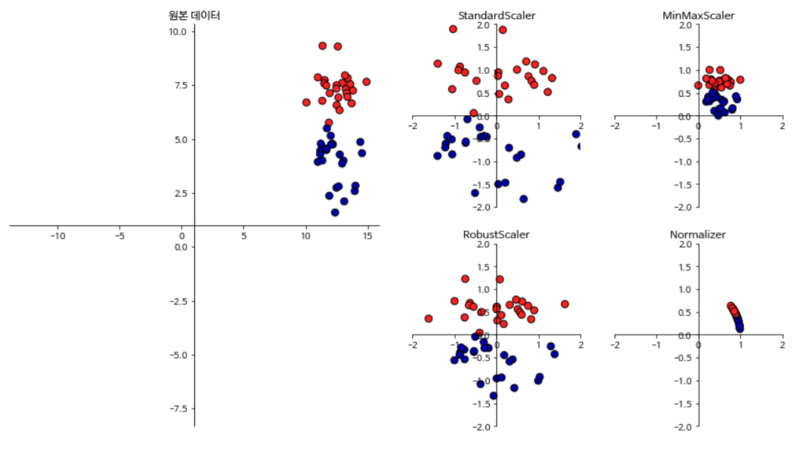
Normalization vs. Standardization


참고로, 표준화와 정규화는 데이터의 스케일을 조정해 다루기 쉽게 만들어줄 뿐 데이터의 분포 모양을 변경하지는 않음
-> sklearn.preprocessing.StandardScaler, sklearn.preprocessing.MinMaxScaler
Batch Normalization
개념

Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Training Deep Neural Networks is complicated by the fact that the distribution of each layer's inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful param
arxiv.org
- Standardization과 굉장히 유사, 감마와 베타값이 추가됐을 뿐
- 감마가 1, 베타가 0이면 statndardization과 똑같음
- 감마와 베타값이 왜 추가됐을까?
- 감마와 베타 값을 넣는 이유는 데이터를 계속 normalize하게 되면 활성화 함수의 비선형 성질을 잃게 되는데 이 문제를 완화하기 위함
- 왜 normalization이 비선형 성질을 잃게 만들까? normalization은 선형변환이기 때문
- 선형 변환이 뭔데?
- 선형 대수학에서 사용되는 개념
- 두 벡터 공간 간의 관계를 나타내는 선형 함수
- 특히, 주어진 벡터 공간의 각 원소에 대해 일정한 규칙을 적용하여 다른 벡터 공간으로 변환하는 함수
- 예를 들어, 정규 분포를 standardization을 하게 되면 다양한 정규 분포를 비교할 수 있듯이 비교 가능한 다른 벡터공간으로 변환해준 것
- 선형 변환이 뭔데?
- 왜 normalization이 비선형 성질을 잃게 만들까? normalization은 선형변환이기 때문
- 감마와 베타 값을 넣는 이유는 데이터를 계속 normalize하게 되면 활성화 함수의 비선형 성질을 잃게 되는데 이 문제를 완화하기 위함
- 다른 점은, 감마와 베타값이 backpropagation을 통해 학습된다는 점
- 동작 방식
- 미니배치의 평균과 분산을 이용해서 정규화한 뒤에, scale 및 shift를 감마 값, 베타 값을 통해 변환
- 정규화된 값을 활성화 함수의 입력으로 사용하고, 최종 출력값을 다음 레이어의 입력으로 사용
- 왜 필요하지? 딥러닝에서 왜 중요할까?
- 레이어마다 정규화하는 레이어를 두어, 각 층에서의 활성화 값이 적당히 분포되도록 조정하여 과적합을 방지
구현
33 Batch Norm
Colaboratory notebook
colab.research.google.com
Numpy
import numpy as np
np.random.seed(678)
# create data
global test_data
test_data = np.zeros((30, 32, 32, 1))
for i in range(30):
new_random_image = np.random.randn(32,32) * np.random.randint(5) + np.random.randint(60)
new_random_image = np.expand_dims(new_random_image, axis=2)
test_data[i,:,:,:] = new_random_image
# case 3 batch normalize first 10 using Numpy
case3_data = test_data[:10,:,:,:]
mini_batch_mean = case3_data.sum(axis=0) / len(case3_data)
mini_batch_var = ((case3_data - mini_batch_mean) ** 2).sum(axis=0) / len(case3_data)
case3 = (case3_data - mini_batch_mean) / ((mini_batch_var + 1e-8) ** 0.5)- Numpy에서 np.sum 함수의 axis=0 : x축을 기준으로 합을 구하는 방식 (>>출처)
-> 미니배치간의 평균을 구하는 것으로 보임
Tensorflow
import numpy as np
import tensorflow as tf
np.random.seed(678)
tf.set_random_seed(678)
config = tf.ConfigProto(device_count = {'GPU': 0})
sess = tf.InteractiveSession(config=config)
# create data
global test_data
test_data = np.zeros((30, 32, 32, 1))
for i in range(30):
new_random_image = np.random.randn(32,32) * np.random.randint(5) + np.random.randint(60)
new_random_image = np.expand_dims(new_random_image, axis=2)
test_data[i,:,:,:] = new_random_image
# case 3 batch normalize first 10 using Tensorflow
case3_data = test_data[:10,:,:,:]
case3 = tf.nn.batch_normalization(case3_data,
mean = case3_data.mean(axis=0),
variance = case3_data.var(axis=0),
offset = 0.0, scale = 1.0,
variance_epsilon = 1e-8
).eval()