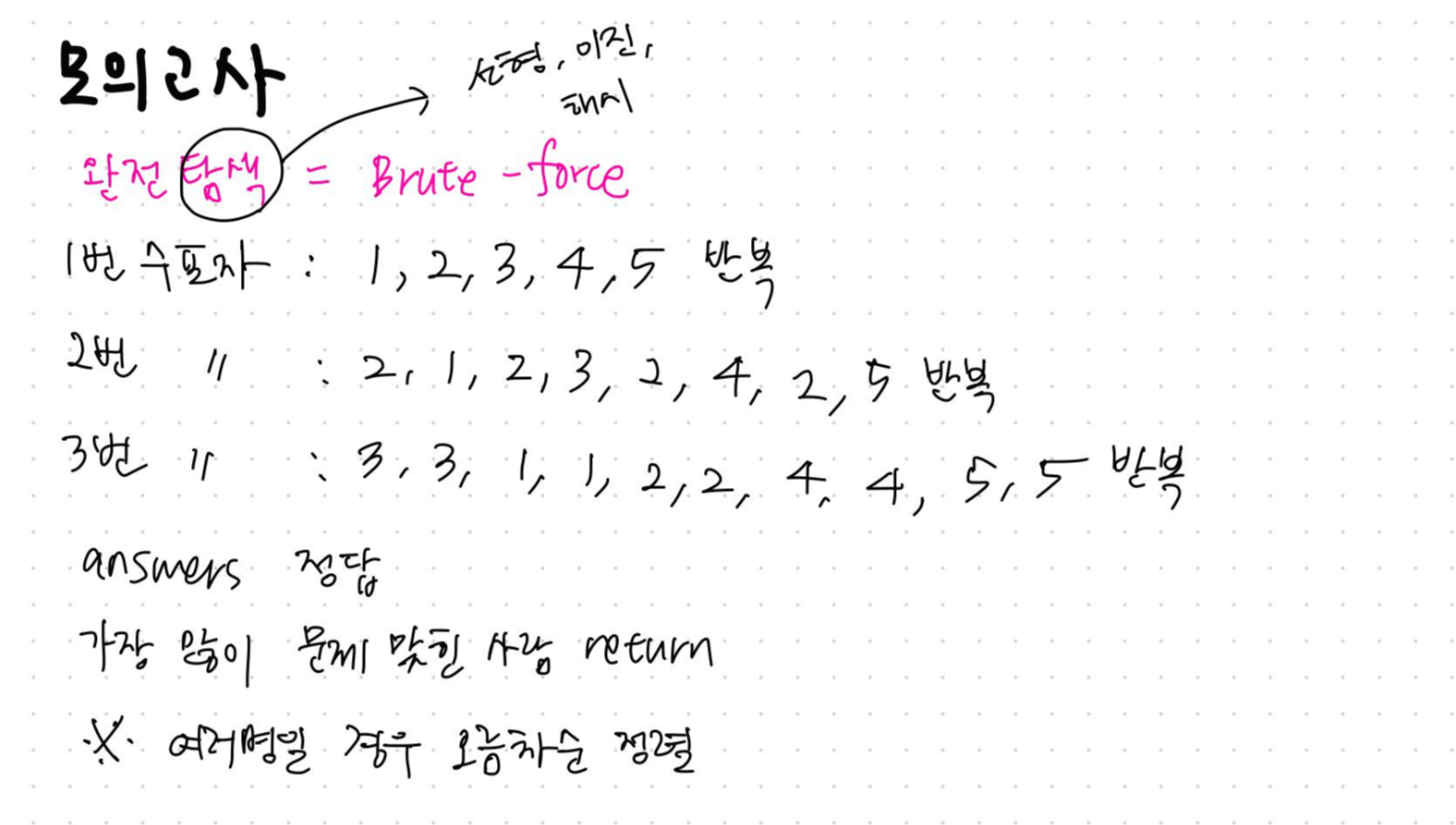
풀이 과정

늘 문제 전체를 캡처하고 싶은데 문제가 너무 길어 다 캡처하기 힘들 때가 있다. 예를 들면 크레인 인형 뽑기 게임^^ 다행히 이번 문제는 문제 설명이 짧았다. 문제를 읽어보니 각 수포자가 찍는 방식에 패턴이 존재했다. 빨간색 선으로 그어놨는데, 1번 수포자의 경우 1, 2, 3, 4, 5를 반복하고, 2번 수포자의 경우 2, 1, 2, 3, 2, 4, 2, 5를 반복하고, 3번 수포자의 경우 3, 3, 1, 1, 2, 2, 4, 4, 5, 5를 반복한다. 그리고 answers는 문제의 진짜 정답이 순서대로 들은 배열이고, 가장 문제를 많이 맞힌 사람을 return해야 한다. 지금 보니 몇 번 수포자가 정답을 많이 맞혔는지 그 수포자의 번호를 return 하는 게 아니라, 번호가 담긴 배열을 return 해야 하는데 처음 읽을 땐 그걸 놓쳤다^^; 다행히 예제를 통해 알 수 있었지만, 그래도 처음 문제읽을 땐 천천히, 꼼꼼히 읽자!

여기서 주의해야 할 점은 가장 높은 점수를 받은 사람이 한 명이 아니라 여러 명일 수 있다는 것, 그리고 여러명일 경우 오름차순으로 정렬해야 한다는 것! 지난 문제에서 sorted로 오름차순 정렬을 구현했던 생각이 났다.

자, 이번 문제도 다행히 어떤 알고리즘을 이용해서 풀어야 하는지 나와있다. 물론 실전 코딩 테스트의 경우 이런 건 주어지지 않겠지만 지금은 알고리즘을 배우고 있는 과정이기 때문에 완전 탐색을 활용할 필요가 있다. 포스팅 맨 앞에 [문제 풀면서 작성한 메모]에서도 알 수 있듯 앞으로 알고리즘에 강조를 주기 위해 자주색으로 메모할 예정이다. 그런데 완전 탐색 알고리즘이 뭐지.. 탐색알고리즘이라면 저번에 배운 선형, 이진, 해시 탐색을 말하는 건가? 혹시 몰라 이것도 메모했다. 그리고 앞서 말했듯 지금은 알고리즘을 배우는 과정이므로 완전 탐색을 검색해보았다.
[알고리즘] 🤷♂️ 완전 탐색 알고리즘 / exhaustive search algorithm
출제 빈도 높음 평균 점수 낮음 🤷♂️ 완전 탐색 알고리즘(exhaustive search algorithm)? PS(Problem Solving)을 하는 데 가장 간단하고 쉬운 방법이 무엇일까요? 답은 가능한 경우를 다 해보는 것입.
geonlee.tistory.com
검색해본 결과 가능한 경우를 브루트포스가 바로 완전 탐색 알고리즘이었다! 가능한 경우를 다 해보는 것!! '뭐야? 이것도 알고리즘이라 할 수 있어?'라고 생각할 수 있지만 그렇다. 완전 탐색도 코딩 테스트에서 나오는구나. 이번 문제는 알고리즘을 딱히 활용할 필요도 없겠다는 생각이 들어(왜냐하면 효율성을 생각 안 해도 되니까!) 바로 풀이로 들어갔다.
def solution(answers):
person1 = [1, 2, 3, 4, 5]
person2 = [2, 1, 2, 3, 2, 4, 2, 5]
person3 = [3, 3, 1, 1, 2, 2, 4, 4, 5, 5]
answer = []
cnt = 0
j = 0
for i in range(len(answers)):
if person1[j] == answers[i]:
cnt += 1
j += 1
if j == 5:
j = 0
print(cnt)
return answer
앞서 말했듯 수포자마다 패턴이 존재했으므로, 그 패턴을 person1부터 person3까지 배열로 담아두었다. 여기까지 보면 이 세명의 수포자를 다 포괄하는 알고리즘인가 싶겠지만, 우선 1번 수포자 한정 알고리즘을 만들어보았다. 1번 수포자 한정이므로, 가장 많이 맞춘 사람을 배열에 담아 return하지도 않았다(6번째, 18번째 줄을 보면 알 수 있듯 answer는 건들이지 않았다.) 일단은 몇 개를 맞췄는지에 초점을 맞춰 알고리즘을 짜보았다. 여기서 문제는 person1 배열에 담긴 원소들을 index가 끝나더라도 계속해서 호출해야 했는데, 관련 함수를 찾아보다 없는 것 같아 결국 13~14번째 줄로 구현했다. j라는 index를 따로 두어 for문을 돌때마다 +1해 주다가 j가 5가 되면 다시 0으로 초기화시켜 0, 1, 2, 3, 4만 돌 수 있게끔 한 것이다.

출력 결과 cnt가 첫 번째 케이스의 경우 5, 두 번째 케이스의 경우 2로 잘 세지는 것을 확인했다. 이제 person1뿐만 아니라 person2, person3까지 일반화시키면 된다.
def solution(answers):
person1 = [1, 2, 3, 4, 5]
person2 = [2, 1, 2, 3, 2, 4, 2, 5]
person3 = [3, 3, 1, 1, 2, 2, 4, 4, 5, 5]
count = []
for person in [person1, person2, person3]:
cnt = 0
j = 0
for i in range(len(answers)):
if person[j] == answers[i]:
cnt += 1
j += 1
if j == 5:
j = 0
count.append(cnt)
max_cnt = max(count)
answer = [idx + 1 for idx, value in enumerate(count) if value == max_cnt]
return sorted(answer)
이제는 person2, person3까지 포함하기 때문에 6번째 줄을 보면 '각' 수포자마다 몇 개 맞추었는지 cnt를 저장할 count 배열을 새로 만들었다. 그리고 7번째 줄을 보면 for문을 한 개 더 두어 person1, person2, person3를 순서대로 돌아가게끔 했다. 여기까지는 앞선 코드를 일반화한 것이고, 가장 많이 맞춘 수포자를 담은 배열을 생성하는 18-19번째 줄을 주목할 필요가 있다. for문을 통해 count에 각 수포자가 몇 개 맞추었는지 담겨있을 것이다. max_cnt에 가장 많이 맞춘 개수를 저장하고 19번째 줄에서 리스트 컴프리헨션을 이용해 max_cnt와 같은 값일 경우 인덱스 + 1(index는 0부터 시작하나 수포자 번호는 1부터 시작하므로 +1)을 answer 배열에 담았다. 이건 사실 아래 링크에 도움을 받았다. max값을 가진 index를 가져오는 것은 쉬우나 max값을 가진 index가 여러 개일 경우 index 함수는 가장 먼저 max값을 가진 index '하나'만 가져오는 문제점이 있었다. 그래서 구글링했는데 enumerate로 여러 index를 가져올 수 있는 방법을 제시해주어 바로 적용했다. 그리고 마지막 줄에 sorted(answer)를 return 하여 리스트를 정렬했다.
[PYTHON] 목록에서 최대 값의 모든 위치를 찾는 방법?
목록에서 최대 값의 모든 위치를 찾는 방법? 목록이 있습니다. a = [32, 37, 28, 30, 37, 25, 27, 24, 35, 55, 23, 31, 55, 21, 40, 18, 50, 35, 41, 49, 37, 19, 40, 41, 31] 최대 요소는 55입니다 (9 및 12 위치..
cnpnote.tistory.com
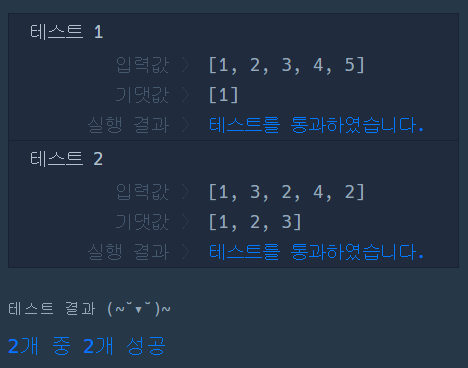
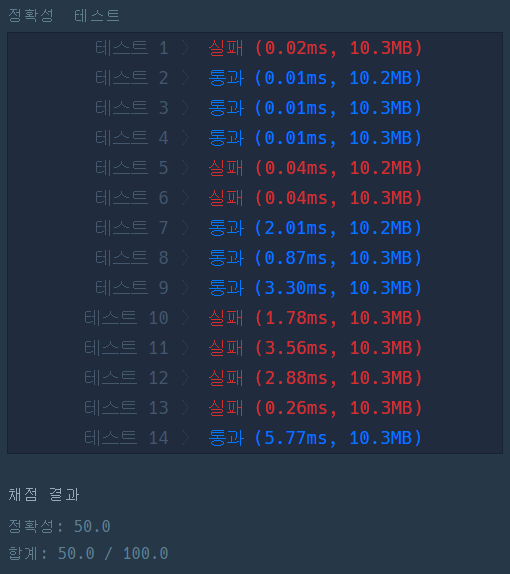
그러나 ㅋㅋㅋㅋㅋ 보기좋게 실패~! 뭐가 문제였을까...? 코드를 다시 찬찬히 살펴봤더니 14번째 줄이 문제였다. if j == 5는 수포자 1번에만 가능한 코드였던 것이다. 수포자 1번의 패턴 길이는 5이므로 j가 0, 1, 2, 3, 4만 반복해야 하지만, 2번의 경우 8이므로 0, 1, 2, 3, 4, 5, 6, 7을 반복해야 한다. 수포자 3번의 경우 패턴 길이가 10이다.
def solution(answers):
person1 = [1, 2, 3, 4, 5]
person2 = [2, 1, 2, 3, 2, 4, 2, 5]
person3 = [3, 3, 1, 1, 2, 2, 4, 4, 5, 5]
count = []
for person in [person1, person2, person3]:
cnt = 0
j = 0
for i in range(len(answers)):
if person[j] == answers[i]:
cnt += 1
j += 1
if j == len(person):
j = 0
count.append(cnt)
max_cnt = max(count)
answer = [idx + 1 for idx, value in enumerate(count) if value == max_cnt]
return sorted(answer)
그래서 14번째 줄에서 5를 각 배열의 길이인 len(person)으로 바꾸어주었다. 처음 일반화하는 과정에서 count를 출력해봤다면 이 실수를 바로잡을 수 있었을 텐데.. 역시 중간중간 출력해보며 잘 되고 있는지를 확인하는게 중요하다.
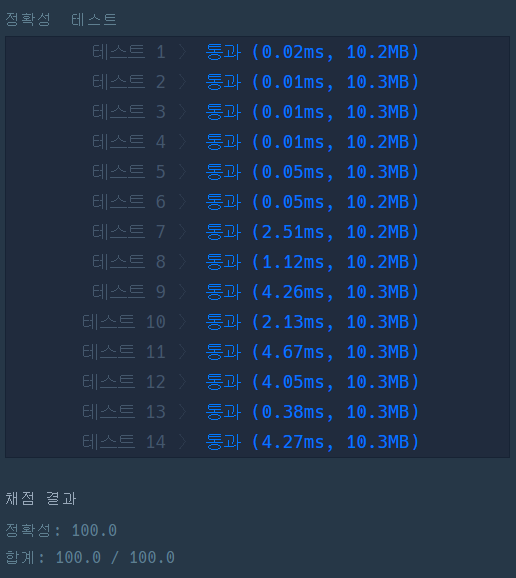
드디어 통과했다!
다른 사람의 풀이
*앞으로 다른 사람의 풀이는 좋아요 가장 많은 순으로 3개씩 꼭 보기로 한다!
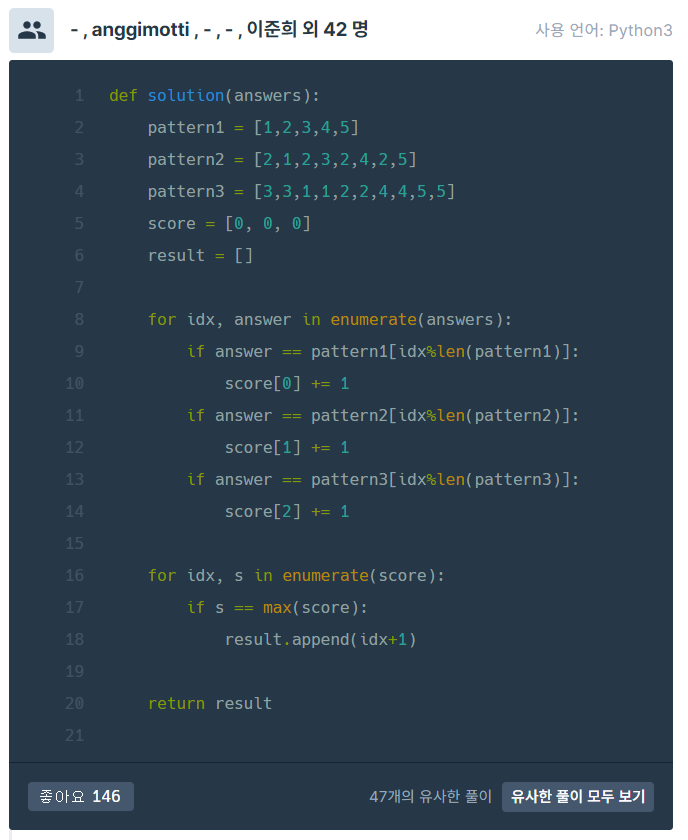
처음으로 나와 비슷한 풀이였던 것 같다. 나의 경우 j가 배열의 가장 끝 인덱스인지 확인하여 0으로 초기화한 반면, 9번째 줄을 보면 나머지 연산을 사용하였다. 신박하다! 매 번 다른 사람의 풀이를 보면서 한 수 배워가는 것 같다. 그리고 변수 cnt를 안 쓰고도 리스트에 바로 +1을 하면 된다는 것도 배울 점이었다. 16~18번째 줄은 나와 같은 코드이나 단지 내가 리스트 컴프리헨션으로 한 줄로 구현했다는 게 달랐다.
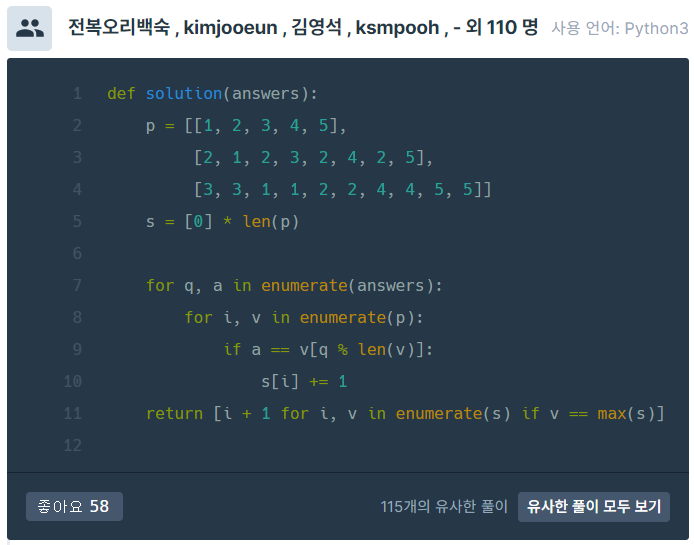
처음 봤을 때 간결하긴 했으나 직관적으로 바로 이해하기는 어려웠다. 특히 s, q, a처럼 변수명이 뭘 뜻하는지를 몰라 좀 어려웠던 것 같다. q는 question, a는 answer인 것 같은데(s는 뭐지?) 약자만 적지 말고 조금 더 적어줬더라면 좋았을 텐데 아쉬웠다. 그렇지만 여전히 배울 점은 있다. [0] * 3을 하면 [0, 0, 0]이 된다는 것을 처음 알았다. 나머지 연산을 활용한 것은 앞선 풀이와 같고, 11번째 줄은 나와 같아 흡족했다. 각 수포자마다 따로 써주었던 앞 풀이와 달리 8번째 줄의 for문을 활용해서 더 간결해졌다.
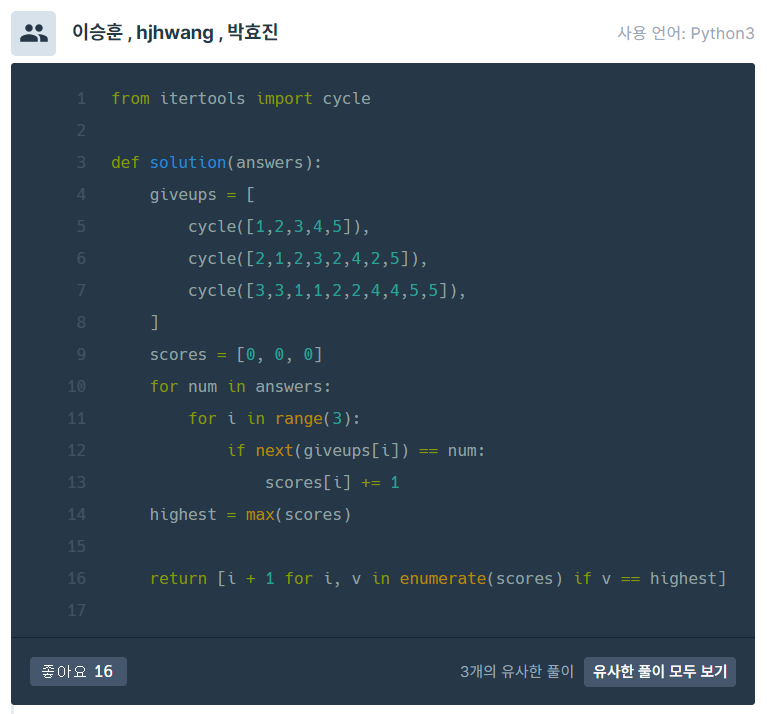
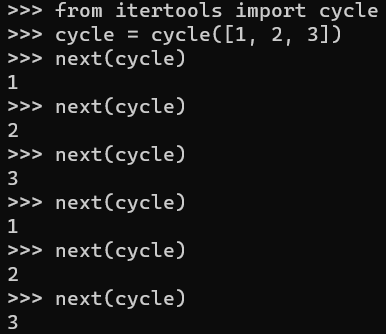
오! 내가 구글링할 땐 못 찾았는데 일정 패턴을 계속해서 반복하여 내뱉도록 도와주는 함수가 바로 cycle이었다!
감사합니다. itertools 라이브러리에 cycle 함수 배워갑니다!
개념 정리
완전 탐색 (Exhaustive Search Algorithm)
= 무식하게 푼다 (Brute-force)
가능한 경우를 다 해보는 것
코드
GitHub - leeejihyun/algorithm: 알고리즘 문제 풀이
알고리즘 문제 풀이. Contribute to leeejihyun/algorithm development by creating an account on GitHub.
github.com
출처
프로그래머스 코딩 테스트 연습 https://programmers.co.kr/learn/challenges
'Computer Science > 알고리즘' 카테고리의 다른 글
| [이코테] 큰 수의 법칙 (0) | 2022.01.02 |
|---|---|
| [프로그래머스/레벨1] K번째수 (0) | 2021.07.13 |
| [프로그래머스/레벨1] 완주하지 못한 선수 (0) | 2021.01.07 |
| [프로그래머스/레벨1] 두 개 뽑아서 더하기 (0) | 2021.01.05 |
| [프로그래머스/레벨1] 크레인 인형뽑기 게임 (0) | 2021.01.04 |



