
Lab-07-1 Tips
다음은 모두를 위한 딥러닝 시즌 2의 Lab-07-1 Tips를 학습하고 요약정리한 내용입니다. 강의 내용을 기반으로 요약하되, 보충 설명이 필요한 경우 확률론 필기노트와 위키독스를 참고했습니다.
학습 목표
신경망과 관련된 여러가지 팁에 대해 알아본다.
핵심 키워드
최대 가능도 추정(Maximum Likelihood Estimation), 과적합(Overfitting),
규제(Regurlarization), 훈련 데이터셋과 테스트 데이터셋(Training and Test Dataset),
학습률(Learning Rate), 데이터 전처리(Data Preprocessing)
1. Reminder: Maximum Likelihood Estimation(최대 가능도 추정)

Maximum Likelihood Estimation (MLE)란 최대 가능도 추정이라 번역한다. likelihood는 우도라고 부르기도 한다. MLE에 대해 잘 모르거나 MLE를 왜 하는지 모르는 사람들이 많아 이것이 뭔지, 왜 하는지 설명하려 한다.
예를 들어, 압정을 던졌을 때 나올 수 있는 경우는 두가지밖에 없다.
• 납작한 부분이 바닥에 떨어진 경우 → class 1
• 비스듬히 떨어진 경우 → class 2
통계적 실험의 결과가 2가지이므로 베르누이 분포를 따른다고 가정하고, 이 베르누이 시행을 독립적으로 $n=100$번 던졌을 때 class 1이 나온 횟수를 $k=27$이라 하자.

슬라이드에 있는 수식은 성공률 $\theta$인 베르누이 시행을 독립적으로 $n$번 반복한 이항 분포에 대한 확률함수이다. 압정을 던졌을 때 납작한 부분이 떨어지는 횟수를 확률 변수 $K$라 할 때, 이항 분포를 따른다고 가정하자. 관측치(observation) $n=100$, $k=27$을 확률함수에 대입하면 우리가 찾고 싶은 모수 $\theta$에 관한 함수 $f(\theta)$가 나온다. 여기서 $\theta$는 압정을 던졌을 때 납작한 부분이 떨어질 확률(=성공률) $p$일 것이다.
혹시 베르누이 분포와 이항 분포가 기억나지 않는다면 아래 더보기를 참고하자.
• 베르누이 분포(Bernoulli Distribution)
통계적 실험의 결과가 성공 or 실패로 총 2가지일 때 확률변수(random variable) $X$의 값을 성공이면 1, 실패면 0이라 하고 성공확률 $P(X=1) = p$, 실패확률 $P(X=0) = 1-p = q$라 한다.
- 확률변수 $X$의 확률함수는 $f(x) = P(X=x) = p^{x}q^{1-x}, x = 0, 1$
- 확률변수 $X$는 성공률 $p$인 베르누이 분포를 따른다고 하고 $X\sim B(1, p)$로 표기한다.
• 이항 분포(Binomial Distribution)
성공률 $p$인 베르누이 시행을 독립적으로 $n$번 반복할 때 확률변수(random variable) $X$를 성공한 횟수라 한다.
- 확률변수 $X$의 확률함수는 $f(x) = P(X=x) = \binom{n}{x}p^{x}q^{n-x}, x = 0, 1, ..., n$
- 이 때의 확률변수 $X$는 이항분포를 따른다고 하고 $X\sim B(n, p)$로 표기한다.
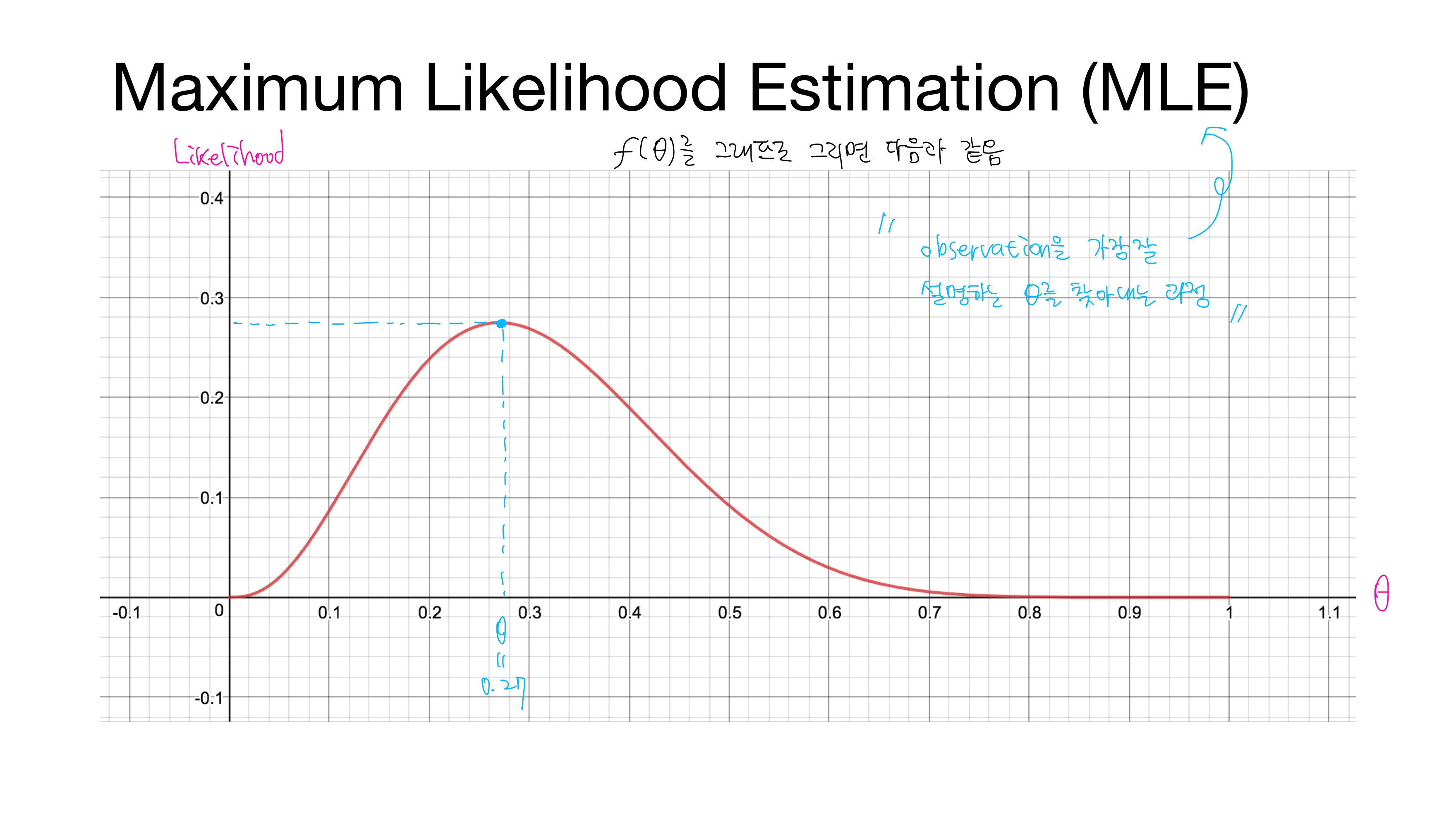
$f(\theta)$를 그래프로 그리면 위와 같다. x축은 $\theta$이고 y축은 확률함수 $f(\theta)$, 즉 일어날 확률인 likelihood이다. 여기서 최대 likelihood를 갖는 $\theta=0.27$이다. 이처럼 관측치를 가장 잘 설명하는 $\theta$를 찾아내는 과정이 바로 MLE이다.
2. Reminder: Optimization via Gradient Descent(경사하강법을 통한 최적화)
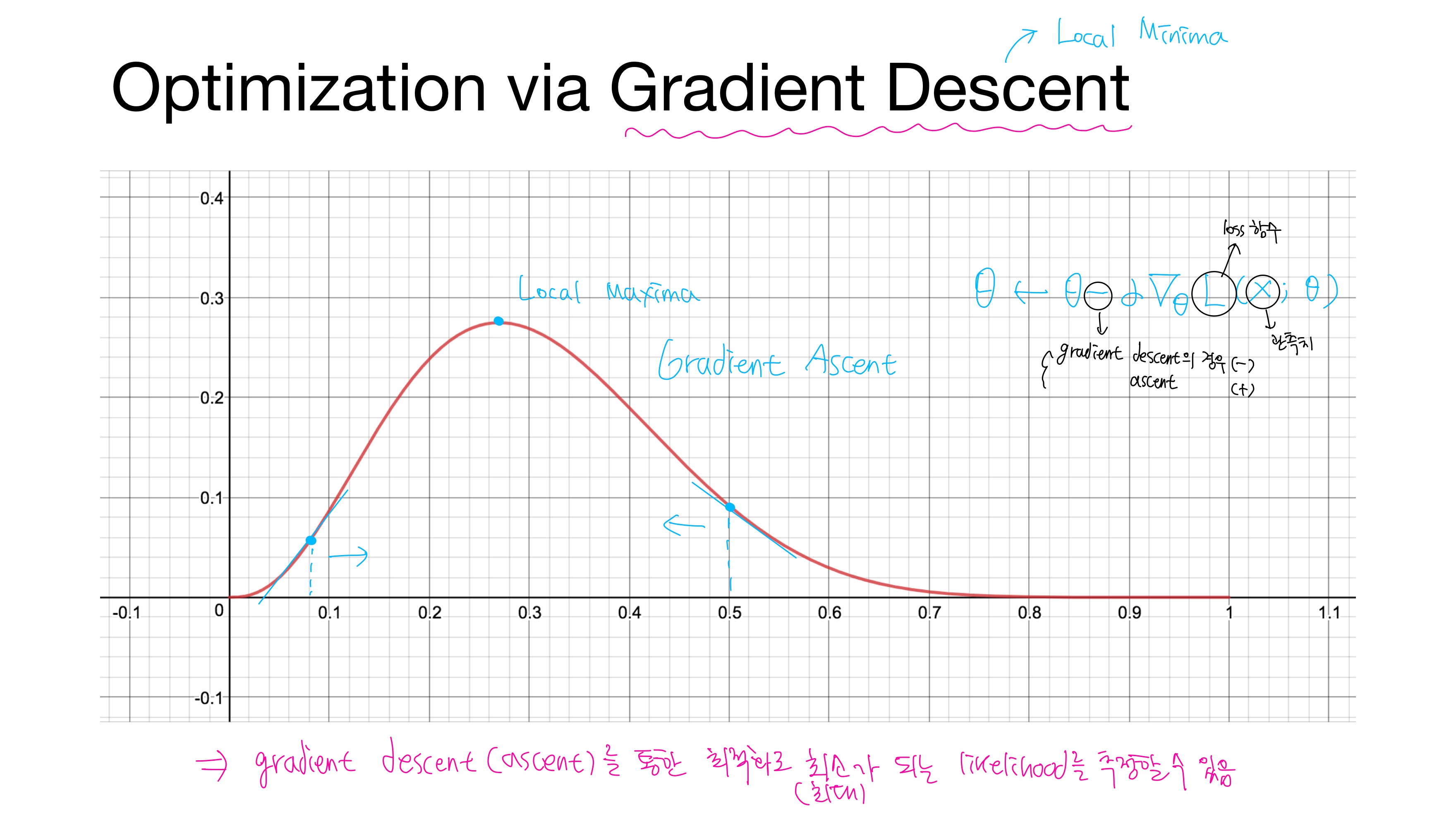
위에서 본 같은 그래프에서 이번에는 기울기를 살펴보자. local maxima로 가기 위해서는 기울기가 양수일 경우 오른쪽으로, 기울기가 음수일 경우 왼쪽으로 가야한다. 이를 Gradient Ascent, 경사상승법이라 한다. 이를 수식으로 나타내면 다음과 같다.
$\theta \leftarrow \theta + \alpha\nabla_{\theta}L(x;\theta)$
$\alpha$는 학습률(learning rate)
$L$은 손실 함수(loss function)
$x; \theta$는 모수 $\theta$에 대한 관측치(observation)
거꾸로 local minima로 가기 위해서는 기울기가 양수일 경우 왼쪽으로, 기울기가 음수일 경우 오른쪽으로 가야한다. 이를 Gradient Descent, 경사하강법이라 한다. 이를 수식으로 나타내면 다음과 같다.
$\theta \leftarrow \theta - \alpha\nabla_{\theta}L(x;\theta)$
이처럼 Gradient Ascent/Descent를 통한 최적화(Optimization)으로 최대/최소가 되는 likelihood를 추정(MLE)할 수 있다.
3. Reminder: Overfitting and Regularization(과적합과 규제)
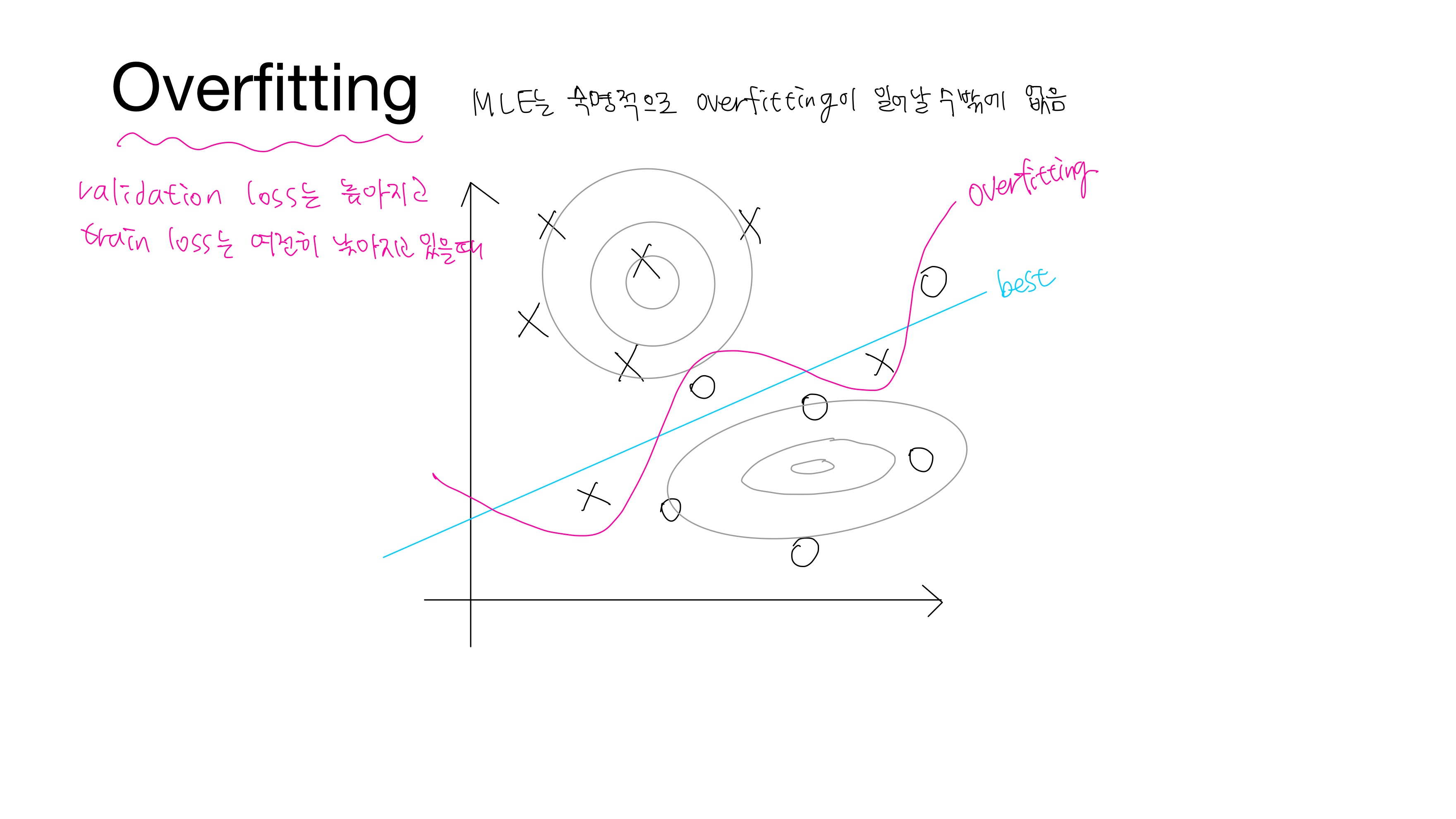
X와 O를 분류하는 문제에서 위와 같이 train data가 분포하고 있다고 하자. X와 O는 각각 회색 선의 분포를 가지고 있다. 분홍색 선은 train data를 과하게 학습한 경우로 validation/test data에서는 정확도가 좋지 않은 현상이 발생한다. train data에 대해서는 loss가 낮지만 validation/test data에 대해서는 loss가 높아지는 상황이다. 이를 과적합(Overfitting)이라 한다. 하늘색 선은 train data를 조금 틀릴 수 있지만 validation/test data에서는 분홍색 선보다 정확도가 높을 것이다. 따라서 하늘색 선이 best라고 할 수 있다.
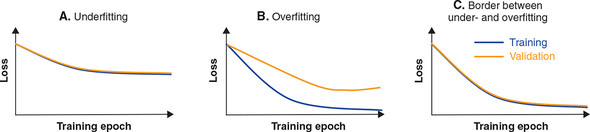
• 과적합, 과대적합(Overfitting)
train data를 과하게 학습한 경우
- train data에 대해서만 과하게 학습하면 validation/test data에 대해서는 정확도가 좋지 않은 현상이 발생
- train data에 대해서는 loss가 낮지만, validation/test data에 대해서는 loss가 높아지는 상황
추가로 과소적합에 대해서도 이야기하려한다.
• 과소적합(Underfitting)
train data를 덜 학습한 경우
- validation/test data의 성능이 올라갈 여지가 있음에도 training을 덜 한 상태
- training 자체가 부족한 상태이므로 overfitting과는 달리 train data에 대해서도 보통 정확도가 낮다는 특징이 있다.
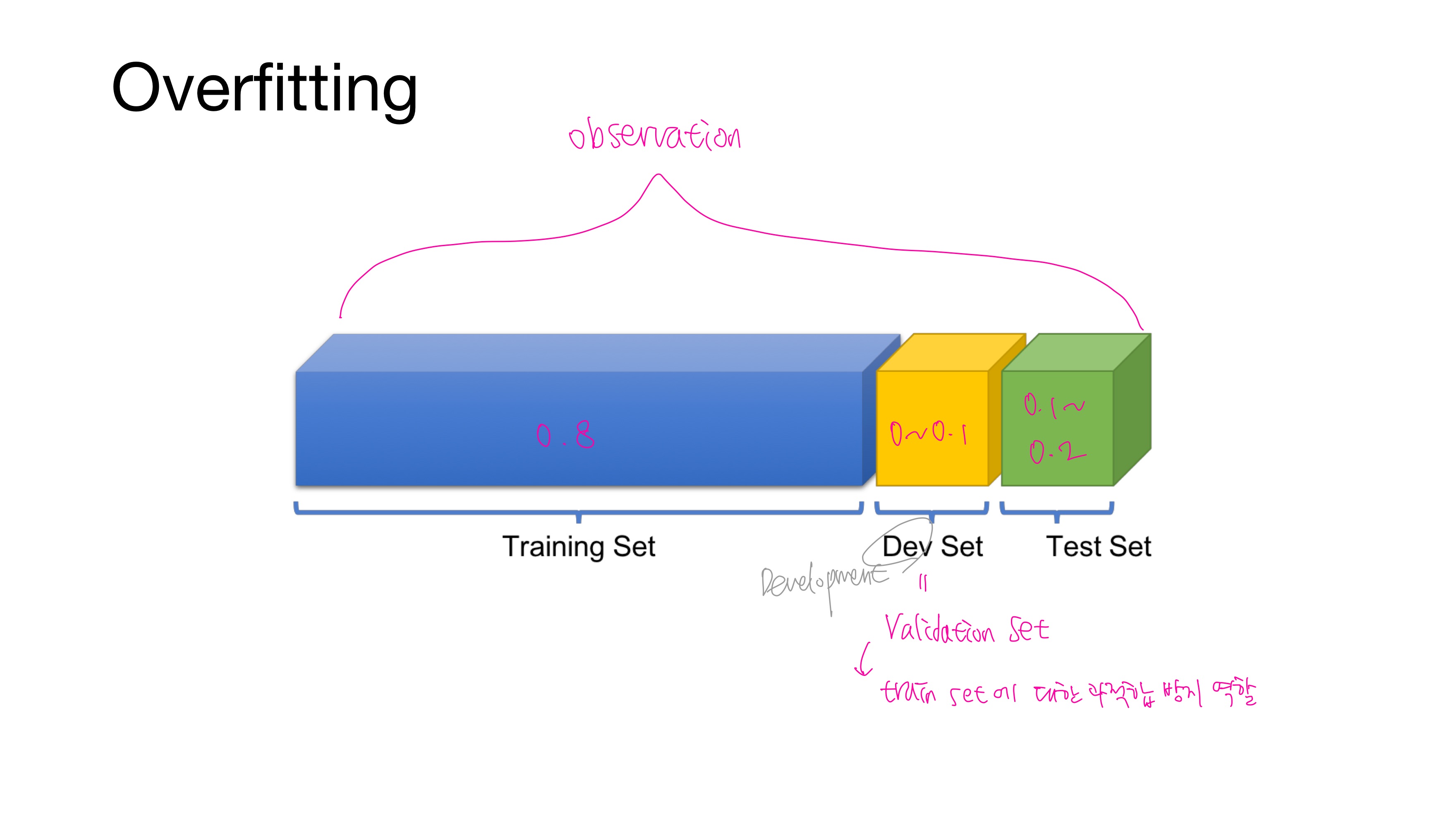
보통 dataset을 Train : Test = 8 : 2로 나누거나 Train : Validation : Test = 8 : 1 : 1로 나눈다. Validaion set은 Development set이라고도 한다.
자, 여기서 궁금한 점은 validation set을 왜 둘까? 혹은 왜 필요할까?
validation set은 모델의 성능을 조정하기 위한 용도이다. 더 정확히는 과적합이 되고 있는지 판단하거나 하이퍼파라미터를 조정하는 역할을 한다.
비유하자면 train data는 문제지, validation data는 모의고사, test data는 실력을 최종적으로 평가하는 수능이라고 볼 수 있다. 만약 validation data와 test data를 나눌만큼 데이터가 충분하지 않다면 k-폴드 교차 검증(k-fold cross validation)이라는 방법을 사용하기도 한다.

overfitting을 막기 위해서는 train loss는 계속해서 낮아지고 있는데 validation/test loss가 증가하기 시작하는 바로 그 시점에서 모수를 선택하면 된다. 여기서 모수는 파라미터를 의미한다.

과적합을 막는 방법들은 다음과 같다.
1. More Data(데이터의 양 늘리기)
만약, 데이터의 양이 적을 경우에는 의도적으로 기존의 데이터를 조금씩 변형하고 추가하여 데이터의 양을 늘리기도 하는데 이를 데이터 증식 또는 증강(Data Augmentation)이라고 한다. 이미지의 경우에는 데이터 증식이 많이 사용되는데 이미지를 돌리거나 노이즈를 추가하고, 일부분을 수정하는 등으로 데이터를 증식시킨다.
2. Less features(피쳐 수 줄이기) 등으로 모델의 복잡도 줄이기
인공 신경망의 복잡도는 은닉층(hidden layer)의 수나 매개변수의 수 등으로 결정된다. 모델의 복잡도를 줄여도 과적합을 막을 수 있다.
3. 가중치 규제(Regularization) 적용하기
• L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가, L1 norm이라고도 함.
L1 규제를 사용하면 비용 함수가 최소가 되게 하는 가중치와 편향을 찾는 동시에 가중치들의 절대값의 합도 최소가 되어야 한다. 이렇게 되면, 가중치 w의 값들은 0 또는 0에 가까이 작아져야 하므로 어떤 특성들은 모델을 만들 때 거의 사용되지 않게 된다.
→ 어떤 특성들이 모델에 영향을 주고 있는지를 정확히 판단하고자 할 때 유용
• L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가, L2 norm이라고도 함. 인공신경망에서는 weight decay라고도 부름.
L2 규제는 L1 규제와는 달리 가중치들의 제곱을 최소화하므로 w의 값이 완전히 0이 되기보다는 0에 가까워지기는 경향을 띈다.
→ 어떤 특성들이 모델에 영향을 주고 있는지를 정확히 판단할 필요가 없다면 경험적으로는 L2 규제가 더 잘 동작하므로 L2 규제를 더 권장
책에 따라서는 Regularization를 '정규화'로 번역하기도 하지만, 이는 정규화(Normalization)와 혼동될 수 있으므로 '규제'라는 번역이 바람직한 것 같다.

Regularization에는 다음과 같은 방법이 있다.
• Early Stopping : validation/test loss가 더이상 낮아지지 않을 때 stop
• Reducing Network size : 딥러닝에 한해서 neural network의 사이즈를 줄이는 것도 좋은 방법
• Weight Decay : 위에서 말한 L2 규제
• 드롭아웃(Dropout), 배치 정규화(Batch Normalization) : 딥러닝에 한해서 가장 많이 쓰는 방법으로 다음에 따로 챕터로 배울 예정

앞서 overfitting을 막는 방법들에 대해 배웠는데 Deep Neural Network를 훈련시키기 위한 기본 접근은 다음과 같다.
① 신경망 구조를 만든다(input size와 output size는 여기서 fix!)
② 훈련시키고 모델이 과적합되었는지 확인한다.
a. 만약 과적합되지 않았다면, 모델 사이즈를 더 깊고 넓게 늘린다.
b. 만약 과적합되었다면, 드롭아웃이나 배치정규화 같은 규제를 추가한다.
③ ②를 반복한다.
4. Training and Test Dataset

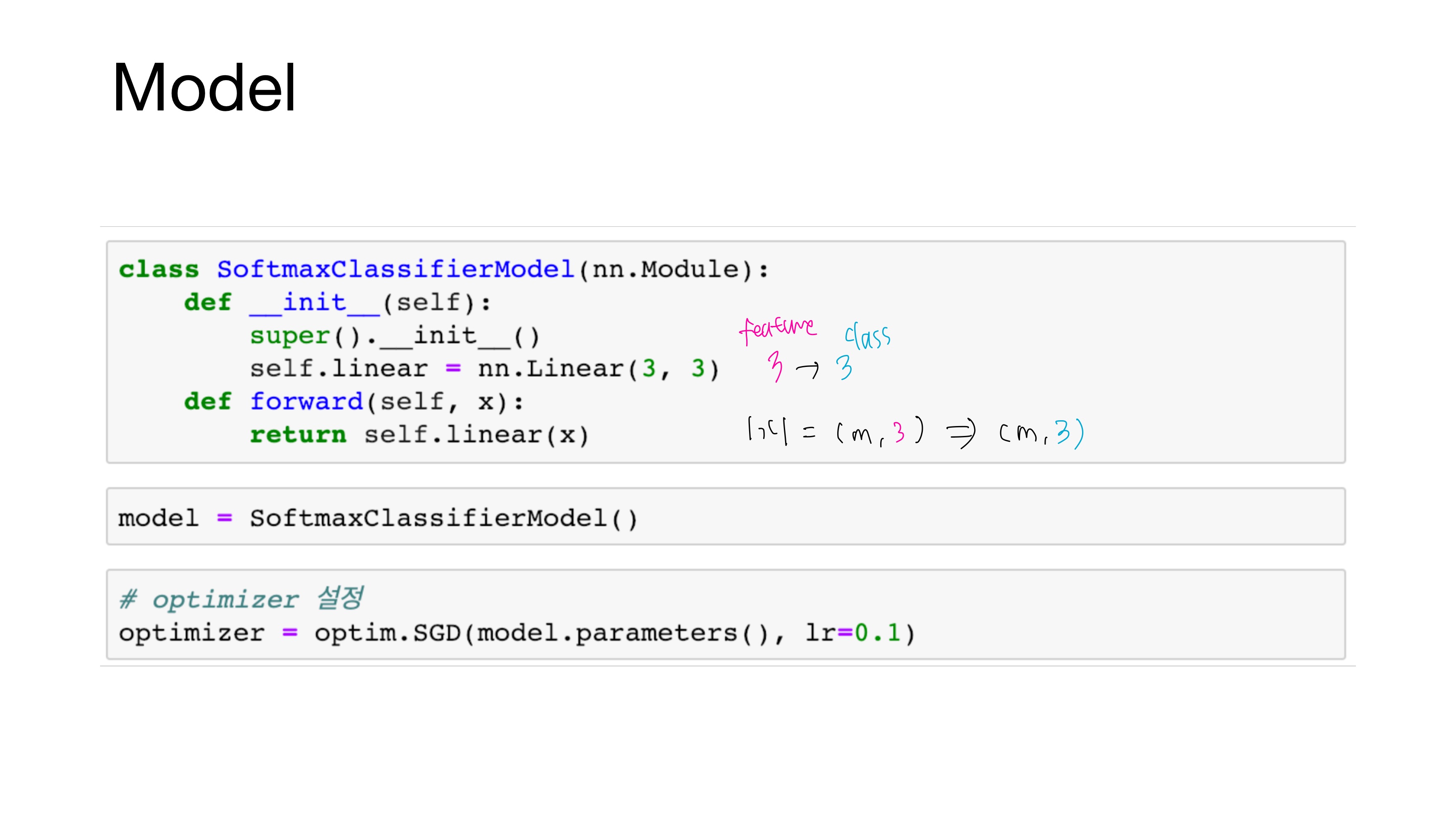


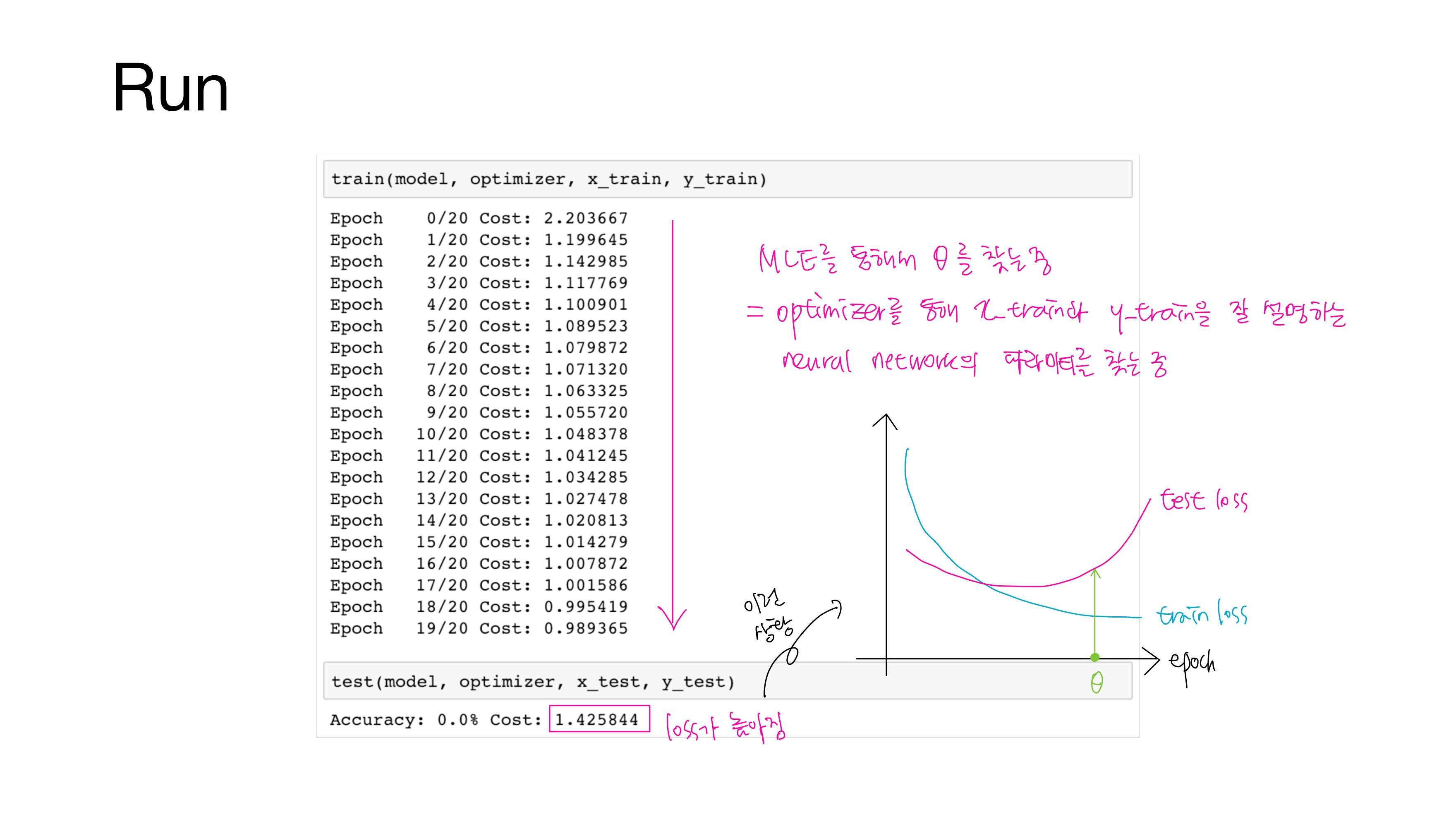
앞서 MLE를 통해 $\theta$를 찾는다고 했는데, 이는 곧 optimizer를 통해 관측치 x_train과 y_train을 잘 설명하는 신경망의 매개변수(가중치와 편향)를 찾는 것과 같다.
현재 train loss는 낮아지는데 test loss는 높으므로 모델이 과적합된 상황이다.
5. Learning Rate(학습률)
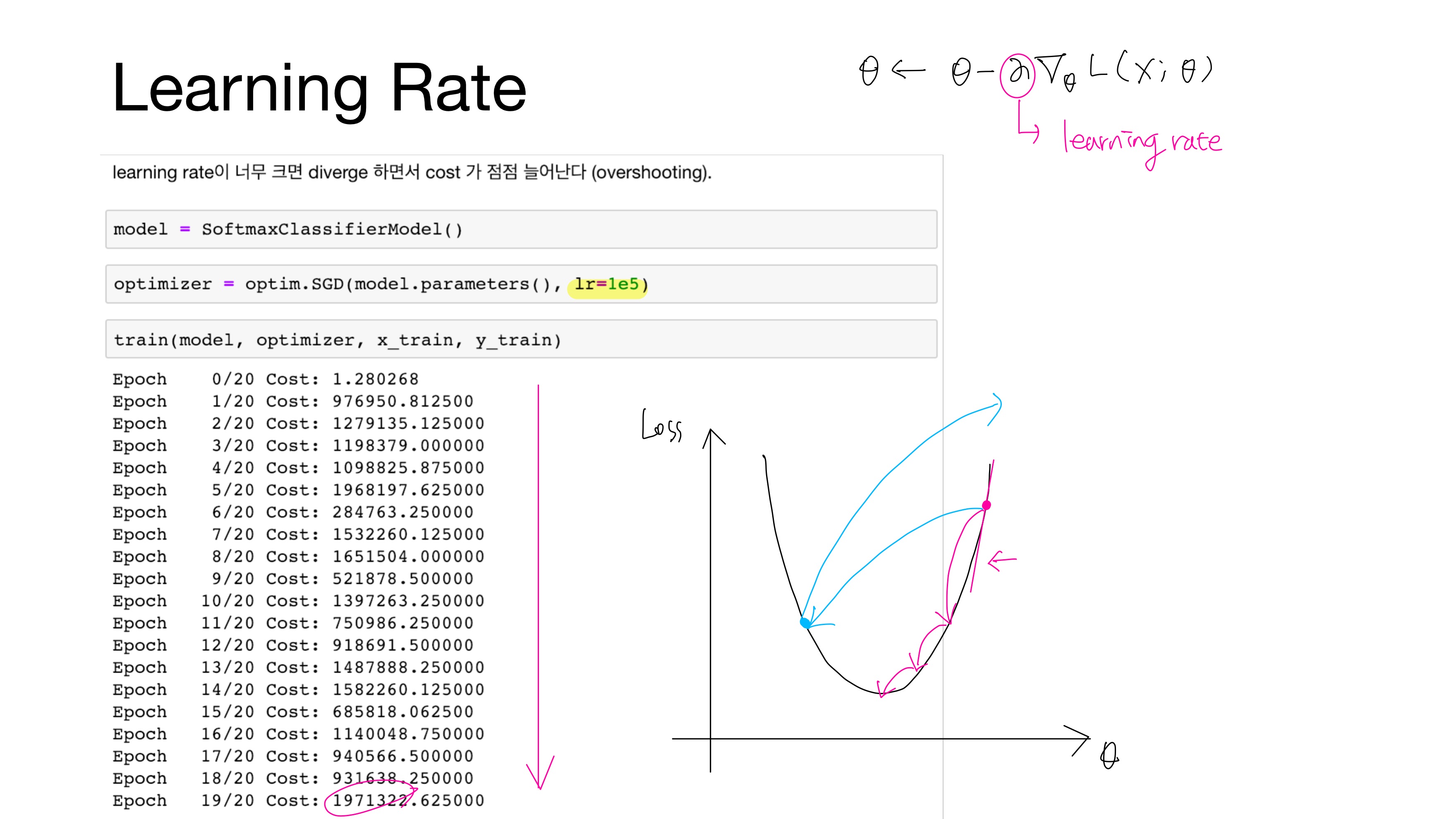
learning rate가 너무 클 경우 발산(diverge)하면서 cost가 점점 늘어난다. 이 상황을 기울기 폭주(Gradient Exploding)이라 한다.
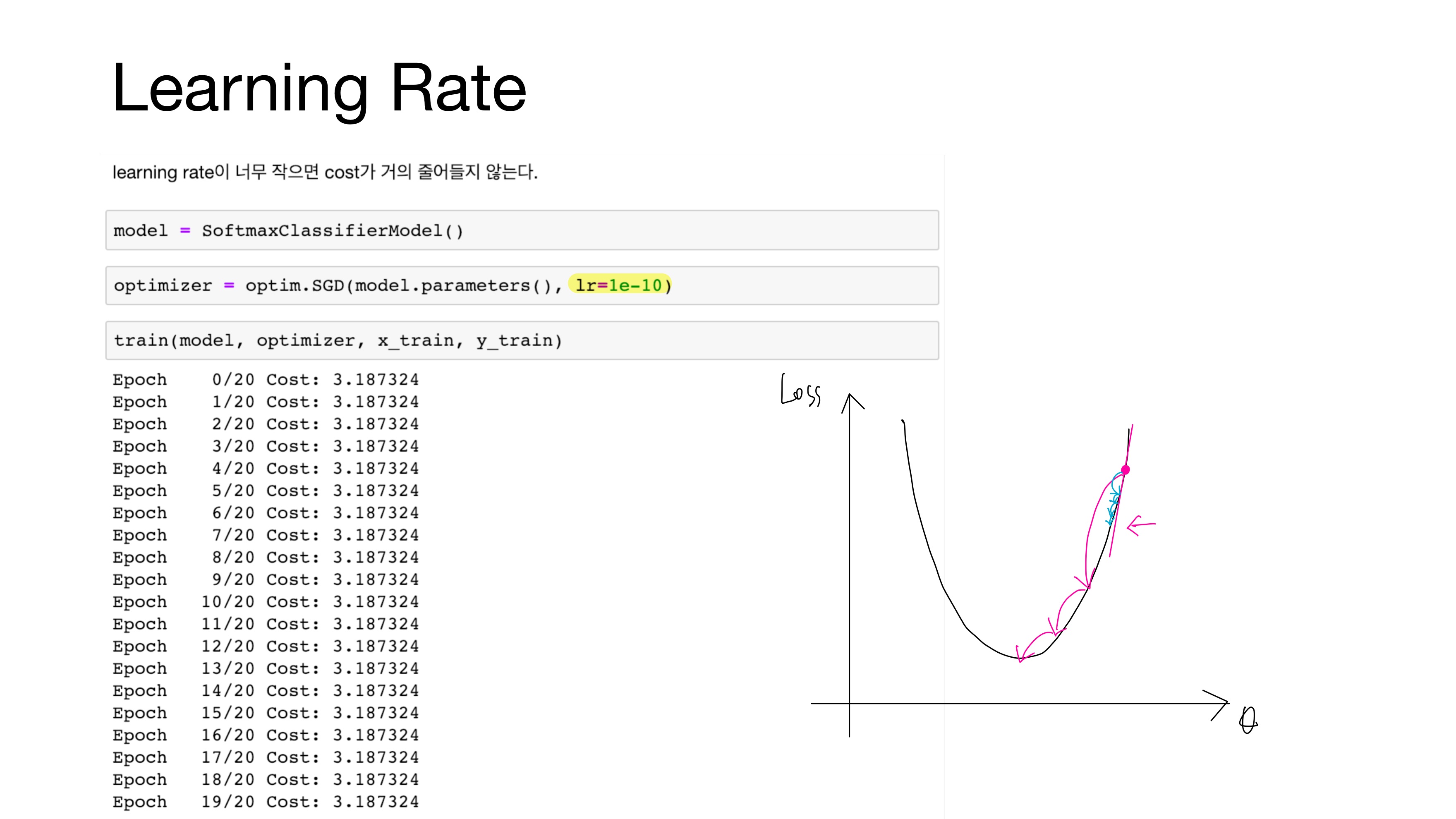
learning rate가 너무 작을 경우 cost가 거의 줄어들지 않는다. 이 상황을 기울기 소실(Gradient Vanishing)이라 한다.
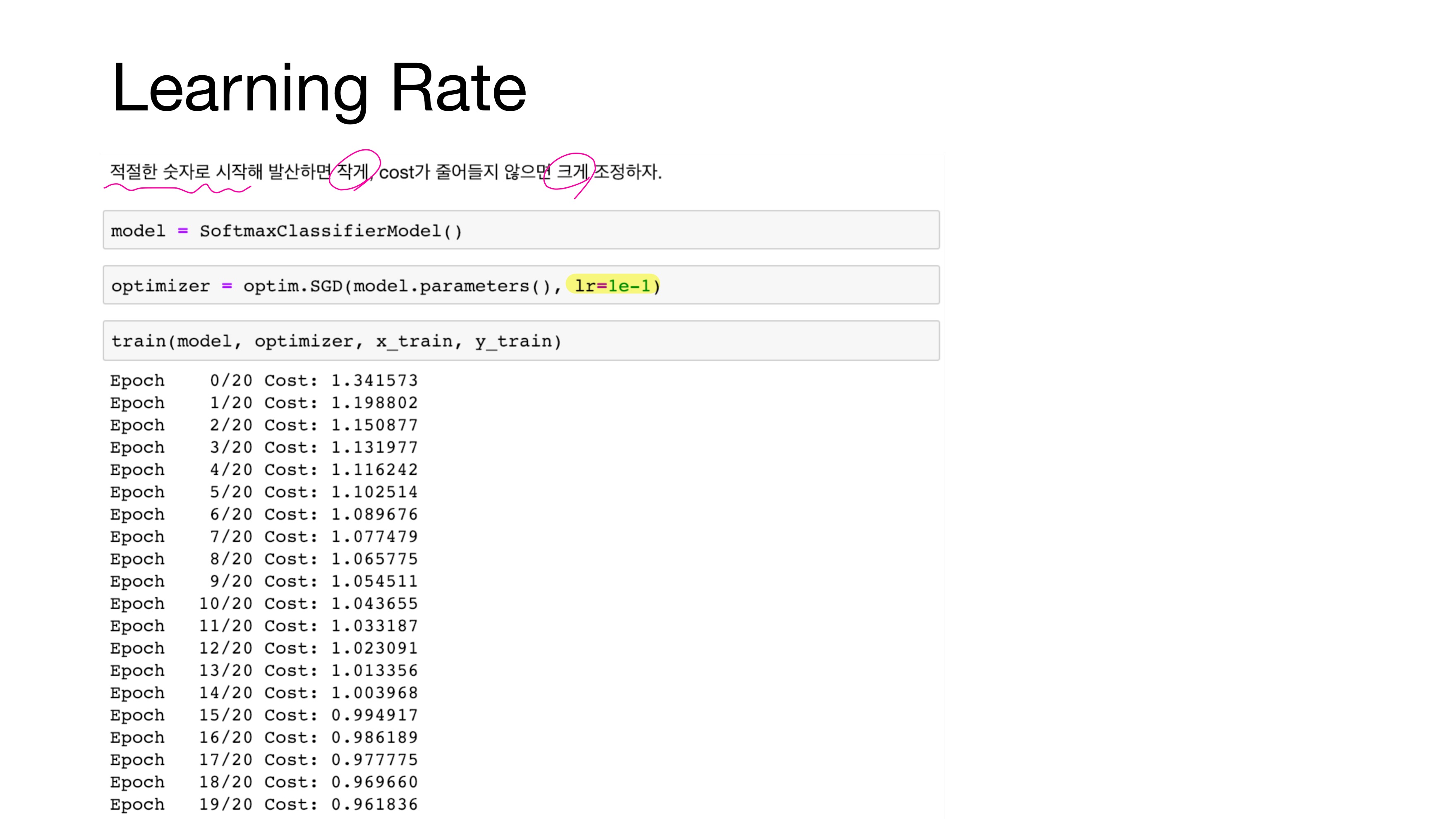
따라서 적절한 숫자로 시작해 발산하면 작게, cost가 줄어들지 않으면 크게 조정해야 한다. 데이터에 따라 다르지만 보통 0.1도 큰 편에 속해 1e-3으로 시작하는 편이다.
6. Data Preprocessing(전처리)





'Deep Learning > Pytorch' 카테고리의 다른 글
| [모두를 위한 딥러닝/시즌2] Lab-06 Softmax Classification (0) | 2021.02.04 |
|---|---|
| [모두를 위한 딥러닝/시즌2] Lab-05 Logistic Regression (0) | 2021.01.30 |
| [모두를 위한 딥러닝/시즌2] Lab-04-2 Loading Data (0) | 2021.01.29 |
| [모두를 위한 딥러닝/시즌2] Lab-04-1 Multivariable Linear regression (0) | 2021.01.29 |
| [모두를 위한 딥러닝/시즌2] Lab-02, 03 Linear regression (0) | 2021.01.29 |



