<밑바닥부터 시작하는 딥러닝> 책을 읽으며 딥러닝 관련 용어를 정리해보았다. 용어 출처의 대부분은 책이며, 간혹 설명이 잘 안나와있는 것은 구글링하여 보완했다. 구글링한 용어들은 하이퍼링크에 출처를 표기해놓았다. 참고로 예시는 회색, Tip은 파란색으로 표시했다.
딥러닝 용어 정리
브로드캐스트(broadcast)
• 흩뿌리다, 퍼뜨리다, 확대된다는 뜻
• 원소별로(element-wise) 연산하는 것
Ex) Pandas에서 시리즈나 데이터프레임에 있는 모든 데이터에 대해 한 번에 연산하는 것
Ex) Numpy 배열과 스칼라값의 연산을 Numpy 배열의 원소 각각과 스칼라값의 연산으로 바꿔 수행하는 것
퍼셉트론(perceptron)
= 인공 뉴런, 단순 퍼셉트론, 단층 퍼셉트론(single-layer perceptron)
• 다수의 신호를 입력받아 하나의 신호를 출력하는 알고리즘
• 단층 네트워크에서 계단 함수를 활성화 함수로 사용한 모델
가중치(weight)
각 입력 신호가 결과에 주는 영향력(중요도)를 조절하는 매개변수
편향(bias)
뉴런이 얼마나 쉽게 활성화하느냐(결과로 1을 출력)를 조정하는 매개변수
Ex) b가 -20.0이면 각 입력 신호에 가중치를 곱한 값들의 합이 20.0을 넘지 않으면 뉴런이 활성화되지 않음!
배타적 논리합(exclusive OR, XOR/EOR/EXOR)
같으면 0, 다르면 1
다층 퍼셉트론(multi-layer perceptron)
• 층이 여러 개인 퍼셉트론
• 신경망(여러 층으로 구성되고 시그모이드 함수 등의 매끈한 활성화 함수를 사용하는 네트워크)
활성화 함수(activation function)
입력 신호의 총합을 출력 신호로 변환하는 함수
계단 함수(step function)
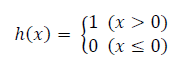
임계값을 경계로 출력이 바뀌는 함수
선형 함수(linear function)
선형인 함수
$y = ax + b$
비선형 함수(nonlinear function)
선형이 아닌 함수
ReLU 함수(Rectified Linear Unit)
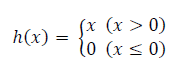
입력이 0을 넘으면 그 입력을 그대로 출력하고, 0이하이면 0을 출력하는 함수
내적(inner product)
= 점곱(dot product), 스칼라곱(scalar product)
외적(outer product)
= 교차곱(cross product), 벡터곱(vector product)
항등 함수(identity function)
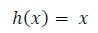
• 입력을 그대로 출력하는 함수
• 회귀에서 사용하는 출력층의 활성화 함수
소프트맥스 함수(softmax function)
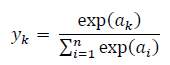
-n은 출력층의 뉴런 수
-$y_{k}$는 그중 k번째 출력
-$a_{k}$는 입력 신호
• 다중 클래스 분류에서 사용하는 출력층의 활성화 함수
• scores를 probabilities로 바꿔줌.
Tip) 실제로 현업에서는 출력층의 소프트맥스 함수 생략
시그모이드 함수(sigmoid function)

이진 클래스 분류에서 사용하는 출력층의 활성화 함수
순전파(forward propagation)
추론 과정(앞서 학습한 가중치 매개변수를 사용하여 입력 데이터 분류)
오차역전파법(backward propagation of errors)
=역전차법, 역전파
오차를 역으로 전파하는 방법
가중치 초기화(weight initialization)
• Xavier 초기화: 앞 계층의 노드가 $n$개라면 표준편차가 $\sqrt{\frac{1}{n}}$인 분포를 사용
• He 초기화: 앞 계층의 노드가 $n$개라면 표준편차가 $\sqrt{\frac{2}{n}}$인 분포를 사용
Tip) 활성화 함수로 ReLU를 사용할 때는 He 초깃값을, sigmoid나 tanh 등의 S자 모양 곡선일 때는 Xavier 초깃값을 사용!
원-핫 인코딩(one-hot encoding)
• 하나만 hot하다!
• 정답을 뜻하는 원소만 1이고 나머지는 모두 0인 배열
Ex) label이 1부터 5까지 있을 때 3을 원-핫 인코딩하면 [0,0,1,0,0]
정규화(normalization)
최대, 최소값을 이용한 변환(0~1 범위로 변환)
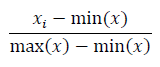
표준화(standardization)
• 평균, 표준편차를 이용한 변환
• 정규화에 포함되어 사용되기도 함
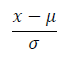
백색화(whitening)
분산을 1로 변화시키고, 변수간 correlation을 제거
cf) 표준화: 분산을 1로 변화시키고, correlation은 그대로 남김
전처리(pre-processing)
신경망의 입력 데이터에 특정 변환을 가하는 것
배치(batch)
• 하나로 묶은 입력 데이터
• 묶음
퍼셉트론 수렴 정리(perceptron convergence theorem)
선형 분리 가능(linearly separable) 문제는 유한 번의 학습을 통해 풀 수 있다는 정리
즉, 선형 분리 가능 문제는 퍼셉트론으로 풀면 됨, but 비선형 분리 문제는 풀 수 X(자동으로 학습할 수 X)
특징(feature)
입력 데이터에서 추출된 본질적인 데이터(중요한 데이터)
종단간 기계학습(end-to-end machine learning)
처음부터 끝까지, 즉 입력에서 출력까지 사람의 개입 없이 학습
과적합(overfitting)
• 한 데이터셋에만 지나치게 최적화된 상태
• Train data에만 지나치게 학습하여 그 외의 데이터에는 제대로 대응(예측/분류)하지 못하는 상태
오차제곱합(sum of squares for error, SSE)
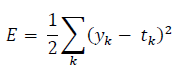
- $y_{k}$는 신경망의 출력(신경망이 추적한 값)
- $t_{k}$는 정답 레이블
- $k$는 데이터의 차원 수
교차 엔트로피 오차(cross entropy error, CEE)
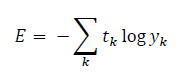
- $y_{k}$는 신경망의 출력(신경망이 추적한 값)
- $t_{k}$는 정답 레이블
- $k$는 데이터의 차원 수
미니배치(mini-batch)
• 신경망을 학습시키기 train data로부터 고른 일부
즉, 전체 train data의 대표로서 무작위로 선택한 작은 덩어리
• 전수조사가 아닌 표본조사로 생각하면 됨!
Ex) 6만장의 train data 중에서 100장을 무작위로 뽑아 그 100장만 사용하여 학습
미분
‘특정 순간’의 변화량
수치 미분(numerical differentiation)
• 아주 작은 차분으로 미분하는 것
• 근사치로 계산하는 방법
Ex) $f(x)=x^{2}$을 수치 미분하면 $\frac{f(x+h)-f(x-h)}{2h}$
해석적 미분(analytic differentiation)
우리가 수학 시간에 배운 바로 그 미분
Ex) $f(x)=x^{2}$을 해석적으로 미분하면 $\frac{df}{dx}=2x$
차분
암의 두 점에서의 함수 값들의 차이
• 중심 차분 or 중앙 차분 $f(x+h)-f(x-h)$
• 전방 차분 $f(x+h)-f(x)$
기울기(gradient)
모든 변수의 편미분을 벡터로 정리한 것
경사법(gradient method)
• 손실함수를 최소화해야 하므로 경사 하강법(gradient descent method, GD)으로 많이 불림
학습률(learning rate)
• 한 번의 학습으로 얼마만큼 학습해야 할지 갱신하는 양. 즉, 매개변수 값을 얼마나 갱신하느냐를 정하는 것
• 각 반복(iteration)에서 파라미터 업데이트의 크기
• 학습률을 높이면 과대적합의 위험
• 학습률을 낮추면 과소적합의 위험
Ex) 데이터를 문제집이라고 비유하면, 문제집에 1~10장까지 있다고 가정할 때 학습률을 높이면 각 반복에서 한번에 두 장씩 보는거고, 학습률을 낮추면 각 반복에서 한번에 한 장씩 본다고 하자. 그러면 학습률이 높을수록 각 반복마다 더 많은 문제를 푸니까 과적합될 수 있다.
즉, 데이터를 skip하는 것이 아니라 더 많이 학습하는 것! 같은 반복 횟수에서 학습률이 높으면 데이터를 더 많이 보는 것이다.
파라미터(parameter)
자동으로 정해지는 매개변수
하이퍼파라미터(hyper parameter)
사람이 직접 설정해야 하는 매개변수
학습(training)
가중치와 편향을 train data에 맞춰 조정하는 과정
확률적 경사 하강법(stochastic gradient descent method, SGD)
확률적으로 무작위로 골라낸 데이터(미니배치)에 대해 수행하는 경사 하강법
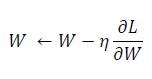
- $W$는 갱신할 가중치 매개변수
- $\frac{\partial L}{\partial W}$은 $W$에 대한 손실 함수의 기울기
- $\eta$는 학습률
에폭(epoch)
1에폭 = training에서 train data를 모두 소진했을 때의 횟수
Ex) train data 10,000개를 100개의 미니배치로 학습할 경우, SGD를 100회 반복하면 모든 train data를 소진하게 됨, 이 경우 1에폭=100회
계산 그래프(computational graph)
계산 과정을 그래프로 나타낸 것
아핀 변환(affine transformation)
기하학에서 행렬의 곱을 부르는 말
아핀(affine) 계층
affine 변환을 수행하는 처리
전치 행렬(transopose matrix)
행렬 M의 (i, j) 위치의 원소를 (j, i)위치로 바꾼 행렬
기울기 확인(gradient check)
수치 미분으로 구한 기울기와 오차역전파법으로 구현한 기울기가 거의 같음을 확인하는 작업
최적화(optimization)
손실 함수의 값을 가능한 한 낮추는 매개변수를 찾는 것
즉, 매개변수의 최적값을 찾는 문제를 푸는 것
모멘텀(momentum)
• 운동량
• 기울기 방향으로 힘을 받아 물체가 가속된다는 물리 법칙을 적용한 최적화 기법
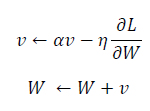
- $W$는 갱신할 가중치 매개변수
- $\frac{\partial L}{\partial W}$은 $W$에 대한 손실 함수의 기울기
- $\eta$는 학습률
- $v$는 물리에서 말하는 속도(velocity)에 해당
- $\alpha v$항은 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할($\alpha$는 0.9 등의 값으로 설정)을 하며 물리에서의 지면 마찰이나 공기 저항에 해당
학습률 감소(learning rate decay)
학습을 진행하면서 학습률을 점차 줄여가는 방법으로,
처음에는 크게 학습하다가 조금씩 작게 학습
Tip) 실제 신경망 학습에 자주 쓰임
AdaGrad
• ‘각각의’ 매개변수에 ‘맞춤형’ 값을 만들어줌
• 개별 매개변수에 적응적으로(adaptive) 학습률을 조정하면서 학습을 진행

- $W$는 갱신할 가중치 매개변수
- $\frac{\partial L}{\partial W}$은 $W$에 대한 손실 함수의 기울기
- $\eta$는 학습률
- ⊙기호는 행렬의 원소별 곱셈을 의미
RMSProp
AdaGrad가 학습을 계속 하다보면 어느 순간 갱신량이 0이 되어 전혀 갱신되지 않게 되는 문제 발생하므로 이를 지수이동평균을 사용하여 개선한 기법
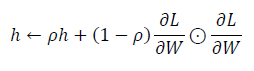
- $W$는 갱신할 가중치 매개변수
- $\frac{\partial L}{\partial W}$은 $W$에 대한 손실 함수의 기울기
- $\eta$는 학습률
- ⊙기호는 행렬의 원소별 곱셈을 의미
- $\rho$는 새로운 하이퍼파라미터로, $\rho$가 작을수록 가장 최신의 기울기를 더 크게 반영
지수이동평균(Exponential Moving Average, EMA)
과거의 모든 기울기를 균일하게 더해가는 것이 아니라, 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영하는 기법
Adam
Momentum + AdaGrad
가중치 감소(weight decay)
학습 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 penalty를 부과하는 것
Tip) 과적합을 막는 방법 중 하나
기울기 소실(gradient vanishing)
• 신경망을 학습시킬 때 역전파의 기울기 값이 점점 작아지다가 사라지는 문제
• 특정 활성화 함수(sigmoid, tanh)를 사용했을 때 생기는 문제로, 이 문제 발생시 제대로 학습이 안됨
배치 정규화(batch normalization)
각 층의 활성화값 분포가 적당히 펴져야 학습이 원활하게 수행되므로
각 층에서의 활성화값이 적당히 분포되도록 조정하는 방법
Tip) 과적합을 막는 방법 중 하나
드롭아웃(dropout)
특정 확률로 뉴런을 임의로(randomly) 삭제하면서 학습하는 방법
Tip) 과적합을 막는 방법 중 하나
그리드 서치(grid search)
하이퍼파라미터 값을 직접 조합 가능한 값으로 정하여 탐색하는 하이퍼파라미터 최적화 방법
랜덤 서치(random search)
범위를 지정하면 임의의 수를 선택하여 탐색하는 하이퍼파라미터 최적화 방법
Tip) 랜덤 서치가 그리드 서치보다 성능이 더 좋음
베이즈 최적화(Bayesian optimization)
베이즈 정리(Bayes’ theorem)를 중심으로 한 하이퍼파라미터 최적화 방법
합성곱(convolution)
공학과 물리학에서 널리 쓰이는 수학적 개념
$f * g = h$
- *는 합성곱 연산
- $f$는 필터
- $g$는 특징 맵
- $h$는 그 결과
주어진 $f$와 $g$를 통해 $h$를 얻는 과정
완전연결(fully-connected)
=전결합
인접하는 계층의 모든 뉴런과 결합되어 있는 것
특징 맵(feature map)
• CNN에서 합성곱 계층의 입출력 데이터를 지칭
• input feature map, output feature map
합성곱 연산
이미지 처리에서 말하는 필터 연산
CNN에서 필터(filter), 커널(kernel)
합성곱층에서의 가중치 파라미터
수용 영역(receptive field)
Filter가 한 번에 볼 수 있는 입력(Input)의 공간 영역
교차상관(cross-correlation)
주어진 필터를 플리핑하지 않은 것
Cf) 합성곱은 주어진 필터를 플리핑한 것, but 이 둘을 명확히 구분하지는 X
행렬의 플리핑(flipping)
원소들을 좌우, 상하로 각 한 번씩 뒤집는 것
패딩(padding)
합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정 값(ex. 0)으로 채우는 것
스트라이드(stride)
• 보폭
• 필터를 적용하는 위치의 간격
풀링(pooling)
세로 및 가로 방향의 공간을 줄이는 연산
Ex) 최대 풀링(max pooling), 평균 풀링(average pooling) 등
im2col(image to column)
입력 데이터를 필터링(가중치 계산)하기 좋게 펼치는(전개하는) 함수
국소적 정규화(Local Response Normalization, LRN)
Relu 함수를 사용할 때 너무 높은 activation 값을 가진 뉴런이 많지 않도록 각 위치마다(하나의 height과 width에서) 모든 channel에 대해 normalize하는 것
Tip) 실제로 큰 도움이 되지 않으므로 현재는 잘 사용하지 X
데이터 확장(data augmentation)
입력 이미지(훈련 이미지)를 알고리즘을 동원해 ‘인위적’으로 확장
Ex) 입력 이미지를 회전하거나 세로로 이동하거나 다양한 방법이 있음
Tip) 모델 학습에 효과적
Top-5 error
확률이 가장 높다고 생각하는 후보 클래스 5개 안에 정답이 포함되지 않은, 즉 5개 모두가 틀린 비율
인셉션 구조(inception)
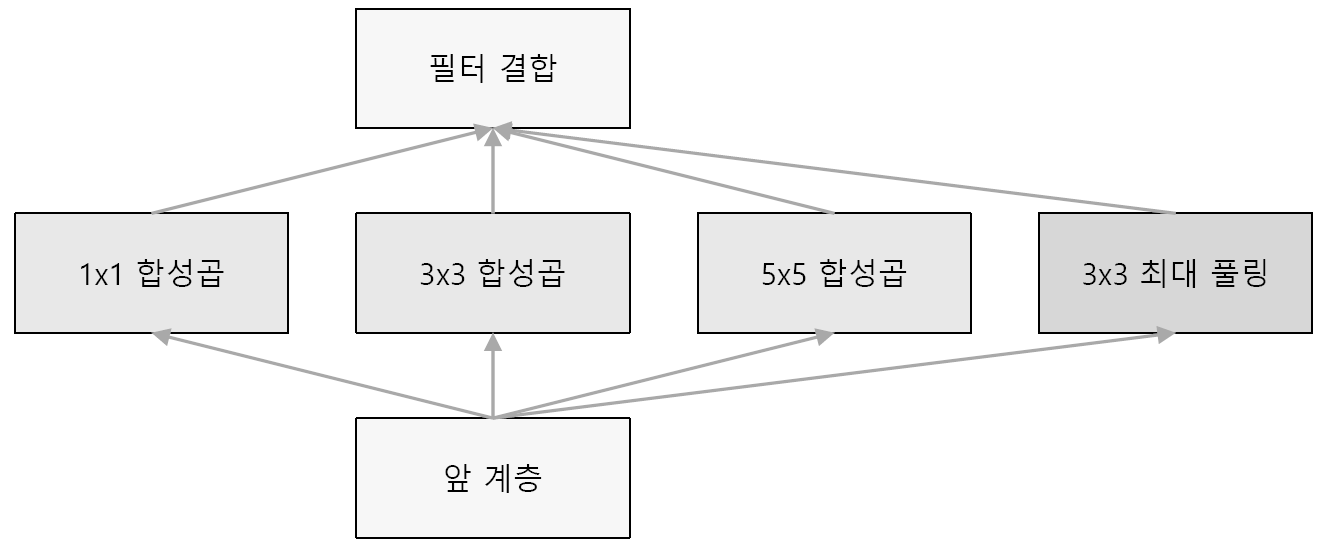
스킵 연결(skip connection)
• 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조
• 입력 데이터를 ‘그대로’ 흘리는 것
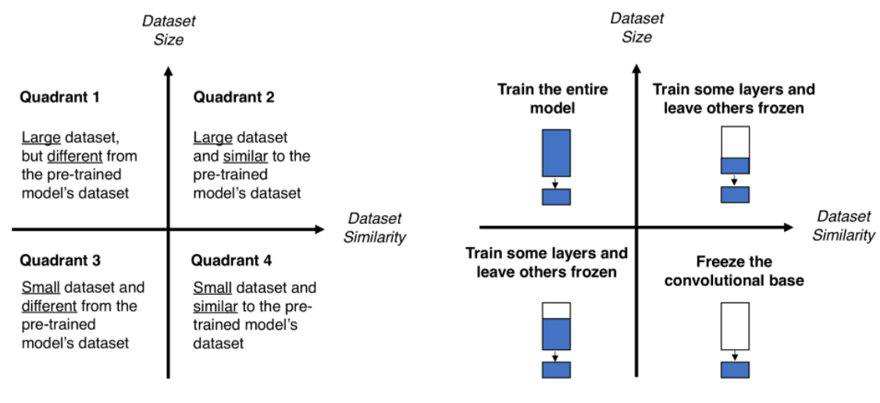
전이 학습(transfer learning)
학습된 가중치(혹은 그 일부)를 다른 신경망에 복사한 다음, 그 상태로 재학습(fine tuning)을 수행
Tip) 데이터셋이 적을 때 특히 유용한 방법이지만, 데이터 특성에 맞게 사용해야 함
GPU computing
GPU로 범용 수치 연산을 수행하는 것
CUDA
엔비디아의 GPU 컴퓨팅용 통합 개발 환경
cuDNN
• CUDA 위에서 동작하는 라이브러리
• 딥러닝에 최적화된 함수 등이 구현되어 있음
수치 정밀도
수치를 몇 비트로 표현하느냐
Ex) 16비트 반정밀도(half-precision)
수용 영역(receptive field)
뉴런에 변화를 일으키는 국소적인 공간 영역
R-CNN(Recognition with Convolutional Neural Network)
사물 검출을 수행하는 방식으로,
후보 영역 추출과 CNN 특징 계산으로 구성됨
후보 영역 추출
사물처럼 보이는 물체를 찾아 처리
Faster R-CNN
후보 영역 추출까지 CNN으로 처리하는 R-CNN
분할(segmentation)
이미지를 픽셀 수준에서 분류하는 문제
FCN, Fully Convolutional Network
• 단 한 번의 forward 처리로 모든 픽셀의 클래스를 분류해주는 놀라운 기법
• 합성곱 계층만으로 구성된 네트워크
보간(interpolation)
알려진 값으로부터 알려진 지점의 값 사이(중간)에 위치한 값을 추정하는 것
Ex) 20살일 때의 키와 40살일 때의 키를 보고 30살에서의 키를 추측
extrapolation
알려진 값들 사이의 값이 아닌 범위를 벗어나 외부의 위치에서의 값을 추정하는 것
Ex) 과거 1살때부터 현재 나이까지의 키를 보고 앞으로 10년 후의 키를 예측하는 것
Tip) interpolation에 비해 훨씬 안정성이 떨어지는 예측 방법
선형 보간(Linear Interpolation)
두 지점 사이의 값을 추정할 때 그 값을 두 지점과의 직선 거리에 따라 선형적으로 결정하는 방법
이중 선형 보간, 쌍선형 보간(Bilinear Interpolation)
1차원에서의 선형 보간법을 2차원으로 확장한 것
역합성곱(deconvolution)
$f * g = h$
- *는 합성곱 연산
- $f$는 필터
- $g$는 특징 맵
- $h$는 그 결과
주어진 $f$와 $h$를 통해 위의 식을 만족하는 $g$를 구하는 연산
NIC, Neural Image Caption
• 딥러닝으로 사진을 캡션하는 대표적인 방법으로,
deep CNN과 RNN으로 구성됨
• CNN으로 사진에서 특징을 추출하고, 그 특징을 RNN에 넘김
• RNN은 CNN이 추출한 특징을 초깃값으로 해서 텍스트를 ‘순환적으로’ 생성
순환 신경망(RNN, Recurrent Nerual Network)
=재귀 신경망
• 순환적 관계를 갖는 신경망
• 자연어나 시계열 데이터 등의 연속된 데이터를 다룰 때 많이 활용
멀티모달 처리(multimodal processing)
사진이나 자연어와 같은 여러 종류의 정보를 조합하고 처리하는 것
딥러닝 용어 책 추천
밑바닥부터 시작하는 딥러닝
직접 구현하고 움직여보며 익히는 가장 쉬운 딥러닝 입문서
www.hanbit.co.kr
딥러닝을 처음 시작하기 가장 좋은 입문서라고 생각한다. 외부 라이브러리는 numpy 정도로 최소한 사용하여 딥러닝을 정말 '밑바닥부터' 구현한다. 그래서 더 직관적으로 개념이 와닿는다. 이론과 실습이 적절히 섞여있어 웬만한 예제는 따라쳐보는 것을 추천한다. 이 책은 1탄은 주로 CNN, 2탄은 RNN으로 알고 있다. 나중에 시간이 되면 2탄도 보고 싶다!
다만 정말 입문서이기 때문에 더 심화된 내용은 다른 책을 봐야 한다. 뿐만 아니라 Tensorflow, Pytorch같은 딥러닝 프레임워크는 사용하지 않는다.
'용어정리' 카테고리의 다른 글
| 머신러닝 용어 정리 (2) | 2024.02.25 |
|---|---|
| 추천 관련 용어 정리 (0) | 2024.02.18 |
| C++ 용어 정리 및 사이트 추천 (0) | 2020.12.26 |
